
Serverless 应用引擎(SAE) 是一款底层基于 Kubernetes,实现了 Serverless 架构与微服务架构结合的云产品。作为一款不断迭代的云产品,在快速发展的过程中也遇到了许多挑战。如何在蓬勃发展的云原生时代中解决这些挑战,并进行可靠快速的云架构升级?SAE 团队和 KubeVela 社区针对这些挑战开展了紧密合作,并给出了云原生下的开源可复制解决方案——KubeVela Workflow。
本文将详细介绍 SAE 使用 KubeVela Workflow 进行架构升级的解决方案,并对多个实践场景进行一一解读。
Serverless 时代下的挑战
Serverless 应用引擎(SAE)是面向业务应用架构、微服务架构的一站式应用托管平台,是一款底层基于 Kubernetes,实现了 Serverless 架构与微服务架构结合的云产品。
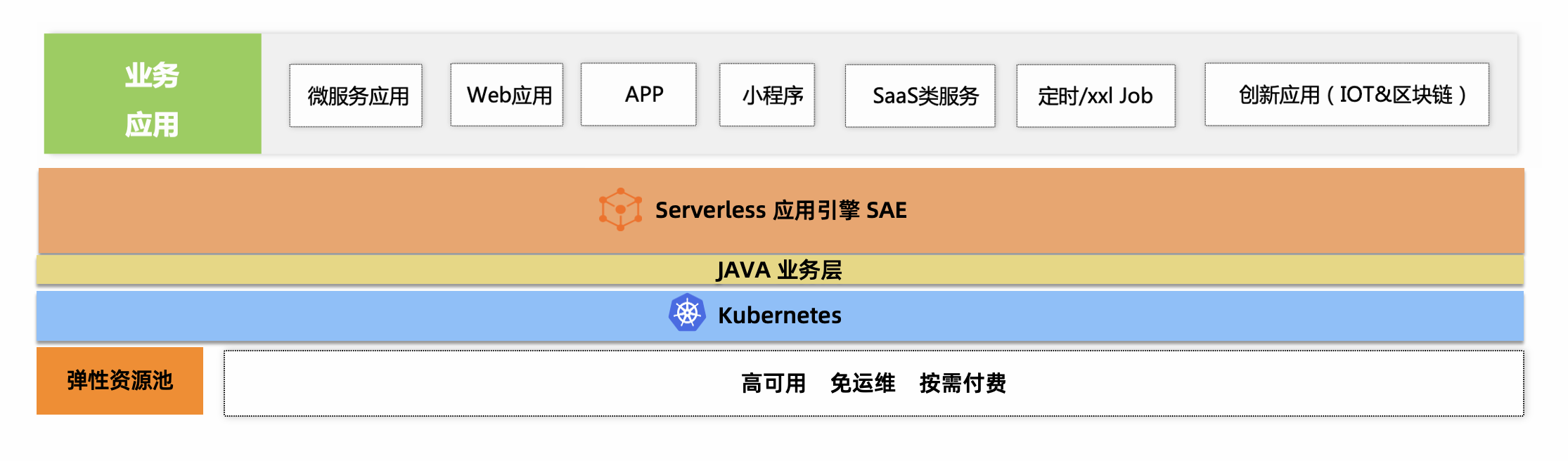
如上架构图,SAE 的用户可以将多种不同类型的业务应用托管在 SAE 之上。而在 SAE 底层,则会通过 JAVA 业务层处理相关的业务逻辑,以及与 Kubernetes 资源进行交互。在最底层,则依靠高可用,免运维,按需付费的弹性资源池。
在这个架构下,SAE 主要依托其 JAVA 业务层为用户提供功能。这样的架构在帮助用户一键式部署应用的同时,也带来了不少挑战。
在 Serverless 持续发展的当下,SAE 主要遇到了三大挑战:
- SAE 内部的工程师在开发运维的过程中,存在着一些复杂且非标准化的运维流程。如何自动化这些复杂的操作,从而降低人力的消耗?
- 随着业务发展,SAE 的应用发布功能受到了大量用户的青睐。用户增长的同时也带来了效率的挑战,在面对大量用户高并发的场景下,如何优化已有的发布功能并提升效率?
- 在 Serverless 持续落地于企业的当下,各大厂商都在不断将产品体系 Serverless 化。在这样的浪潮下,SAE 应该如何在快速对接内部 Serverless 能力,在上线新功能的同时,降低开发成本?
纵观上述三个挑战,不难看出,SAE 需要某种编排引擎来升级发布功能,对接内部能力以及自动化运维操作。
而这个编排引擎需要满足以下条件来解决这些挑战:
- 高可扩展。对于这个编排引擎来说,流程中的节点需要具备高可扩展性,只有这样,才能将原本非标准化且复杂的操作节点化,从而和编排引擎的流程控制能力结合在一起,发挥出 1+1 > 2 的效果,从而降低人力的消耗。
- 轻量高效。这种编排引擎必须高效,且生产可用。这样才能满足 SAE 在大规模用户场景下的高并发需求。
- 强对接和流程控制能力。这个编排引擎需要能够快速业务的原子功能,把原本串联上下游能力的胶水代码转换成编排引擎中的流程,从而降低开发成本。
基于上面这些挑战和思考,SAE 和 KubeVela 社区进行了深度合作,并推出了 KubeVela Workflow 这个项目作为编排引擎。
为什么要用 KubeVela Workflow?
得益于云原生蓬勃的生态发展,社区中已经有许多成熟的工作流项目,如 Tekton,Argo 等。在阿里云内部,也有一些编排引擎的沉淀。那么为什么要“新造一个轮子”,而不使用已有的技术呢?
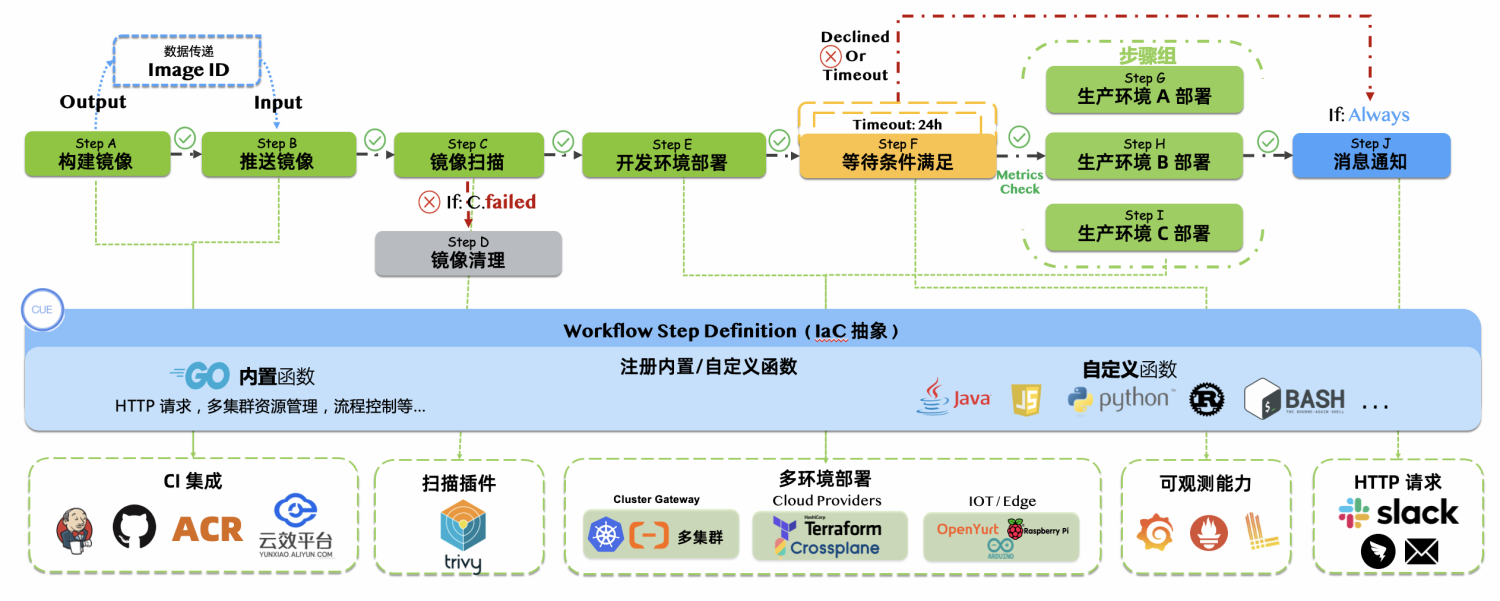
因为 KubeVela Workflow 在设计上有一个非常根本的区别:工作流中的步骤面向云原生 IaC 体系设计,支持抽象封装和复用,相当于你可以直接在步骤中调用自定义函数级别的原子能力,而不仅仅是下发容器。
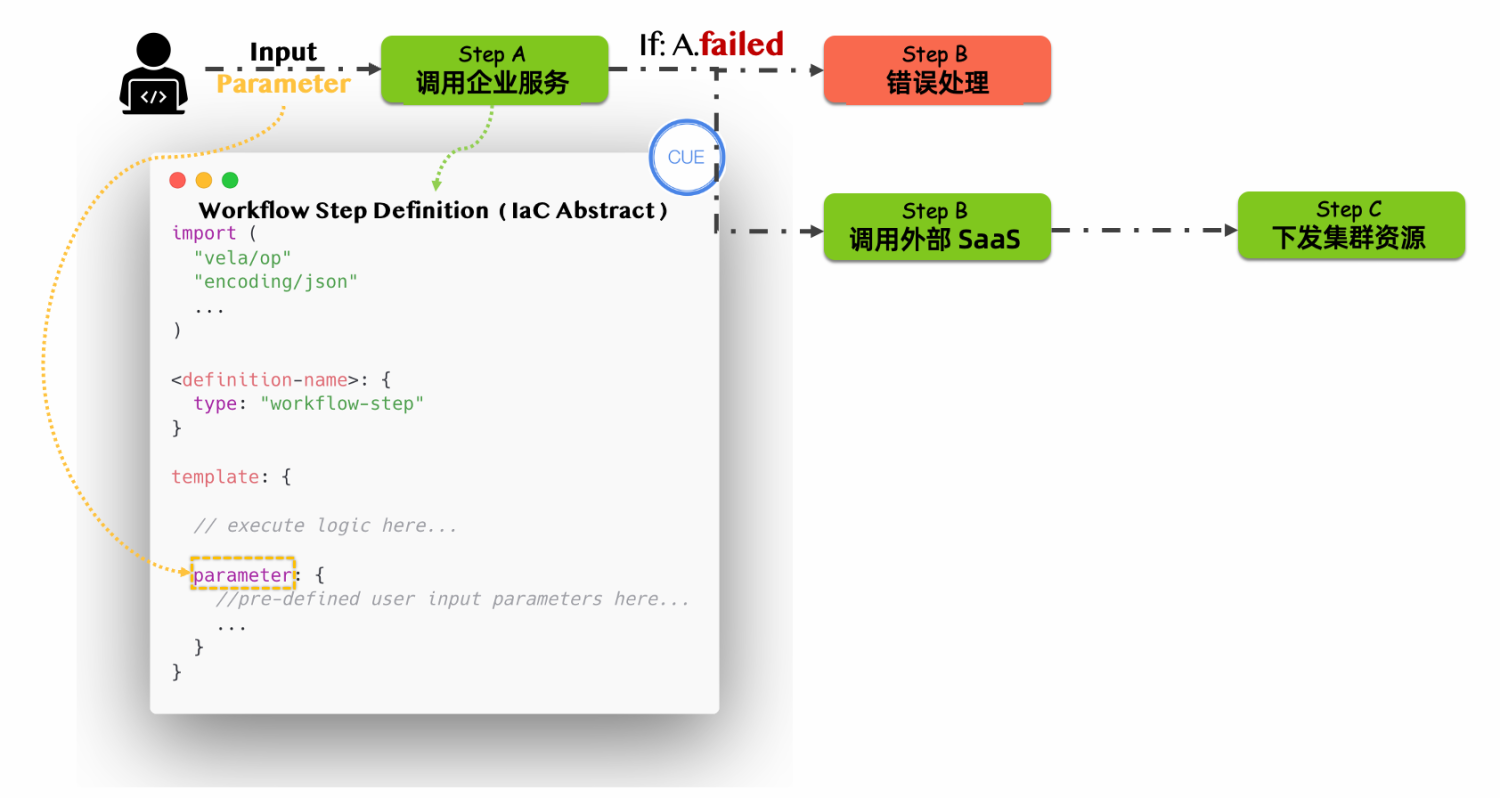
在 KubeVela Workflow 中,每个步骤都有一个步骤类型,而每一种步骤类型,都会对应 WorkflowStepDefinition(工作流步骤定义)这个资源。你可以使用 CUE 语言(一种 IaC 语言,是 JSON 的超集) 来编写这个步骤定义,或者直接使用社区中已经定义好的步骤类型。
你可以简单地将步骤类型定义理解为一个函数声明,每定义一个新的步骤类型,就是在定义一个新的功能函数。函数需要一些输入参数,步骤定义也是一样的。在步骤定义中,你可以通过 parameter 字段声明这个步骤定义需要的输入参数和类型。当工作流开始运行时,工作流控制器会使用用户传入的实际参数值,执行对应步骤定义中的 CUE 代码,就如同执行你的功能函数一样。
有了这样一层步骤的抽象,就为步骤增添了极大的可能性。
- 如果你希望自定义步骤类型,就如同编写一个新的功能函数一样,你可以在步骤定义中直接通过
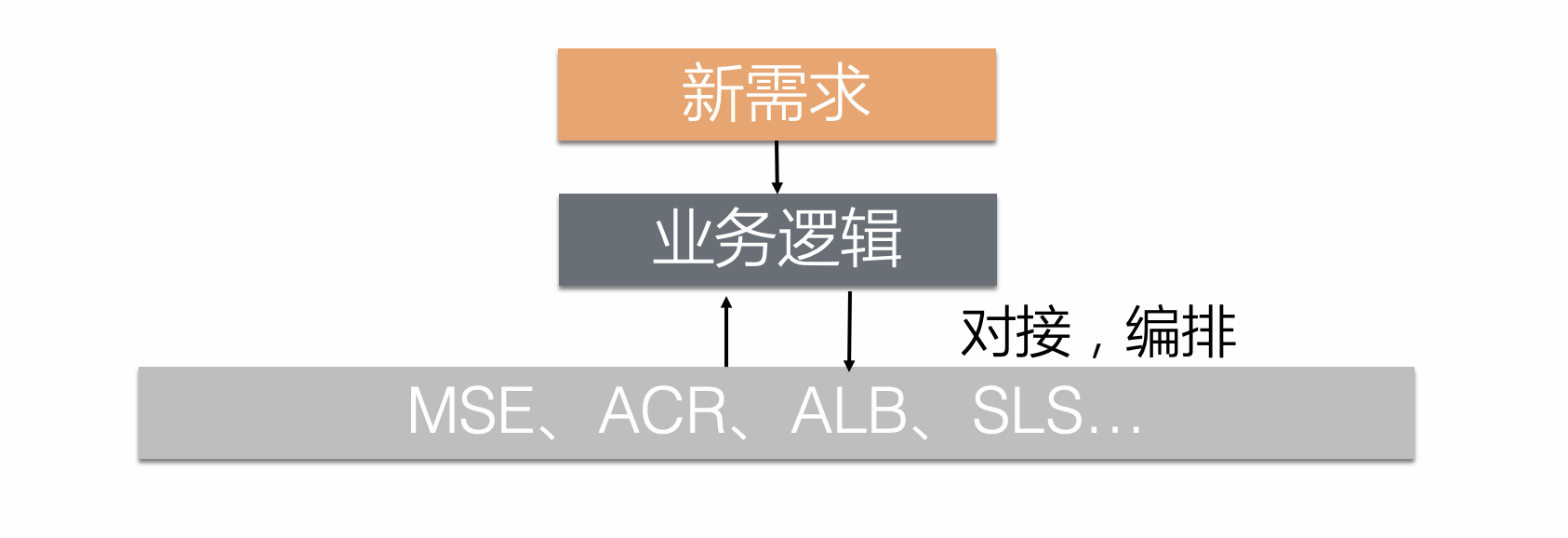
import来引用官方代码包,从而将其他原子能力沉淀到步骤中,包括 HTTP 调用,在多集群中下发,删除,列出资源,条件等待,等等。这也意味着,通过这样一种可编程的步骤类型,你可以轻松对接任意系统。如,在 SAE 的场景下,在步骤定义中解决和内部其他原子能力(如 MSE,ACR,ALB,SLS 等等)的对接,再使用工作流的编排能力来控制流程:
- 如果你只希望使用定义好的步骤,那么,就如同调用一个封装好的第三方功能函数一样,你只需要关心你的输入参数,并且使用对应的步骤类型就可以了。如,一个典型的构建镜像场景。首先,指定步骤类型为
build-push-image,接着,指定你的输入参数:构建镜像的代码来源与分支,构建后镜像名称以及推送到镜像仓库需要使用的秘钥信息。
apiVersion: core.oam.dev/v1alpha1
kind: WorkflowRun
metadata:
name: build-push-image
namespace: default
spec:
workflowSpec:
steps:
- name: build-push
type: build-push-image
properties:
context:
git: github.com/FogDong/simple-web-demo
branch: main
image: fogdong/simple-web-demo:v1
credentials:
image:
name: image-secret
在这样一种架构下,步骤的抽象给步骤本身带来了无限可能性。当你需要在流程中新增一个节点时,你不再需要将业务代码进行“编译-构建-打包”后用 Pod 来执行逻辑,只需要修改步骤定义中的配置代码,再加上工作流引擎本身的编排控制能力,就能够完成新功能的对接。
而这也是 SAE 中使用 KubeVela Workflow 的基石,在可扩展的基础之上,才能充分借助和发挥生态的力量,加速产品的升级。
使用案例
接下来,我们来深入 SAE 中使用 KubeVela Workflow 的场景,从案例中进行更深层的理解。
案例 1: 自动化运维操作
第一个场景,是 SAE 内部的运维工程师的一个自动化运维场景。
在 SAE 内部有这样一个场景,我们会编写并更新一些基础镜像,并且需要将这些镜像预热到多个不同 Region 的集群中,通过镜像预热,来给使用这些基础镜像的用户更好的体验。
原本的操作流程非常复杂,不仅涉及到了使用 ACR 的镜像构建,多个区域的镜像推送,还需要制作镜像缓存的模板,并且将这些镜像缓存推送到不同 Region 的集群当中。这里的 Region 包括上海,美西,深圳,新加坡等等。这些操作是非标准化,且非常耗时的。因为当一个运维需要在本地推送这些镜像到国外的集群当中时,很有可能因为网络带宽的问题而失败。因此,他需要将精力分散到这些原本可以自动化的操作上。
而这也是一个非常适合 KubeVela Workflow 的场景:这些操作里面的每一个步骤,都可以通过可编程的方式转换成工作流里的步骤,从而可以在编排这些步骤的同时,达到可复用的效果。同时,KubeVela Workflow 也提供了一个可视化的 Dashboard,运维人员只需要配置一次流水线模板,之后就可以通过触发执行,或者在每次触发执行时传入特定的运行时参数,来完成流程的自动化。
在这里,简化版的步骤如下:
- 使用 HTTP 请求步骤类型,通过请求 ACR 的服务来构建镜像,并通过参数传递将镜像 ID 传递给下一个步骤。在该步骤定义中,需要等待 ACR 的服务构建完毕后,才结束当前步骤的执行。
- 如果第一步构建失败了,则进行该镜像的错误处理。
- 如果第一步构建成功了,则使用 HTTP 请求步骤来调用镜像缓存构建的服务,并同时将服务的日志作为当前的步骤来源。这里可以直接在 UI 中查看步骤的日志以排查问题,
- 使用一个步骤组,在里面分别使用下发资源类型的步骤来进行上海集群和美西集群的镜像预热:这里会使用 KubeVela Workflow 的多集群管控能力,直接在多集群中下发 ImagePullJob 工作负载,进行镜像预热。
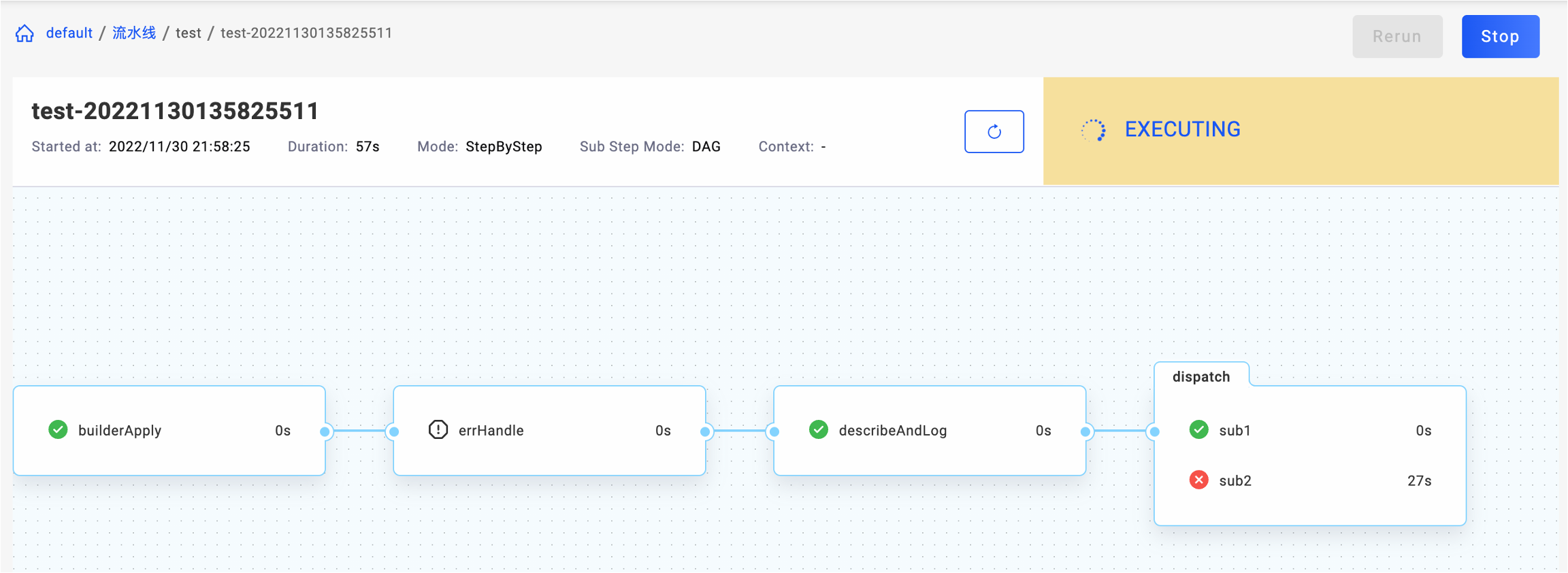
上面这个流程中,如果不使用 KubeVela Workflow,你可能需要写一段业务代码,来串联多个服务和集群。以最后一步,往多集群中下发 ImagePullJob 工作负载为例:你不仅需要管理多集群的配置,还需要 Watch 工作负载(CRD)的状态,直到工作负载的状态变成 Ready,才继续下一步。而这个流程其实对应了一个简单的 Kubernetes Operator 的 Reconcile 逻辑:先是创建或者更新一个资源,如果这个资源的状态符合了预期,则结束此次 Reconcile,如果不符合,则继续等待。
难道我们运维操作中每新增一种资源的管理,就需要实现一个 Operator 吗?有没有什么轻便的方法,可以将我们从复杂的 Operator 开发中解放出来呢?
正是因为 KubeVela Workflow 中步骤的可编程性,能够完全覆盖 SAE 场景中的这些运维操作和资源管理,才能够帮助工程师们降低人力的消耗。类似上面的逻辑,对应到 KubeVela Workflow 的步骤定义中则非常简单,不管是什么类似的资源(或者是一个 HTTP 接口的请求),都可以用类似的步骤模板覆盖:
template: {
// 第一步:从指定集群中读取资源
read: op.#Read & {
value: {
apiVersion: parameter.apiVersion
kind: parameter.kind
metadata: {
name: parameter.name
namespace: parameter.namespace
}
}
cluster: parameter.cluster
}
// 第二步:直到资源状态 Ready,才结束等待,否则步骤会一直等待
wait: op.#ConditionalWait & {
continue: read.value.status != _|_ && read.value.status.phase == "Ready"
}
// 第三步(可选):如果资源 Ready 了,那么...
// 其他逻辑...
// 定义好的参数,用户在使用该步骤类型时需要传入
parameter: {
apiVersion: string
kind: string
name: string
namespace: *context.namespace | string
cluster: *"" | string
}
}
对应到当前这个场景就是:
- 第一步:读取指定集群(如:上海集群)中的 ImagePullJob 状态。
- 第二步:如果 ImagePullJob Ready,镜像已经预热完毕,则当前步骤成功,执行下一个步骤。
- 第三步:当 ImagePullJob Ready 后,清理集群中的 ImagePullJob。
通过这样自定义的方式,不过后续在运维场景下新增了多少 Region 的集群或是新类型的资源,都可以先将集群的 KubeConfig 纳管到 KubeVela Workflow 的管控中后,再使用已经定义好的步骤类型,通过传入不同的集群名或者资源类型,来达到一个简便版的 Kubernetes Operator Reconcile 的过程,从而极大地降低开发成本。
案例 2:优化已有的发布流程
在自动化内部的运维操作之外,升级原本 SAE 的产品架构,从而提升产品的价值和用户的发布效率,也是 SAE 选择 KubeVela Workflow 的重要原因。
原有架构
在 SAE 的发布场景中,一次发布会对应一系列的任务,如:初始化环境,构建镜像,分批发布等等。这一系列任务对应下图中的 SAE Tasks。
在 SAE 原本的架构中,这些任务会被有序地扔给 JAVA Executor 来进行实际的业务逻辑,比如,往 Kubernetes 中下发资源,以及与 MySQL 数据库进行当前任务的状态同步,等等。
在当前的任务完成后,JAVA Executor 会从 SAE 原本的编排引擎中获取下一个任务,同时,这个编排引擎也会不断地将新任务放到最开始的任务列表中。
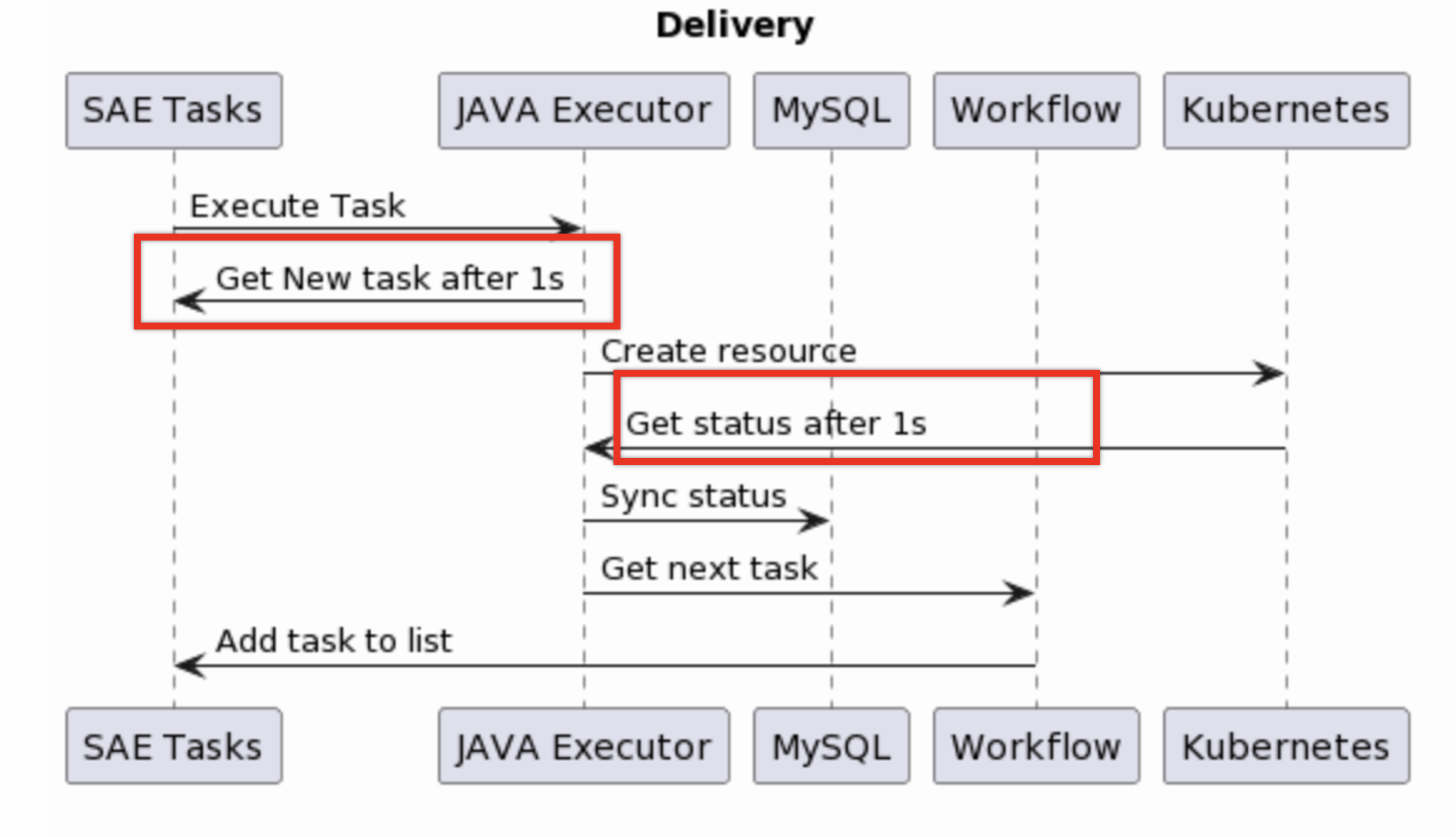
而这个老架构中最大的问题就在于轮询调用, JAVA Executor 会每隔一秒从 SAE 的任务列表中进行获取,查看是否有新任务;同时,JAVA Executor 下发了 Kubernetes 资源后,也会每隔一秒尝试从集群中获取资源的状态。 SAE 原有的业务架构并不是 Kubernetes 生态中的控制器模式,而是轮询的业务模式,如果将编排引擎层升级为事件监听的控制器模式,就能更好地对接整个 Kubernetes 生态,同时提升效率。
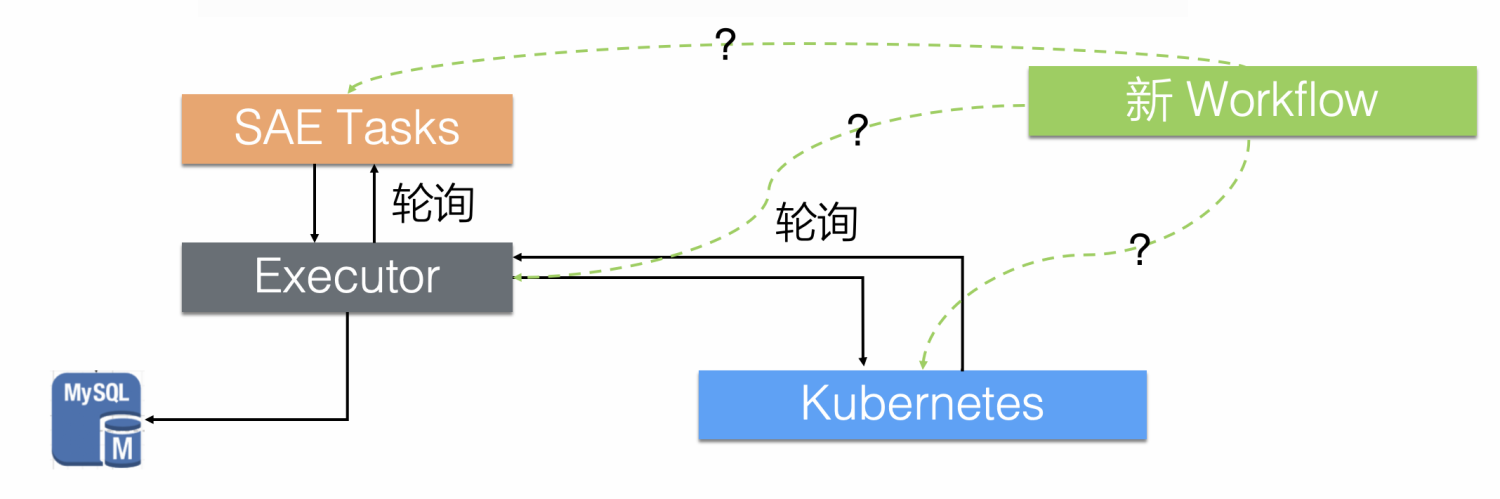
但是在原本的架构中,业务的逻辑耦合较深。如果使用的是传统的以容器为基础下发的云原生工作流的话,SAE 就需要将原本的业务逻辑打包成镜像,维护并更新一大堆镜像制品,这并不是一条可持续发展的道路。我们希望升级后的工作流引擎,能够轻量地对接 SAE 的任务编排,业务执行层以及 Kubernetes 集群。
新架构
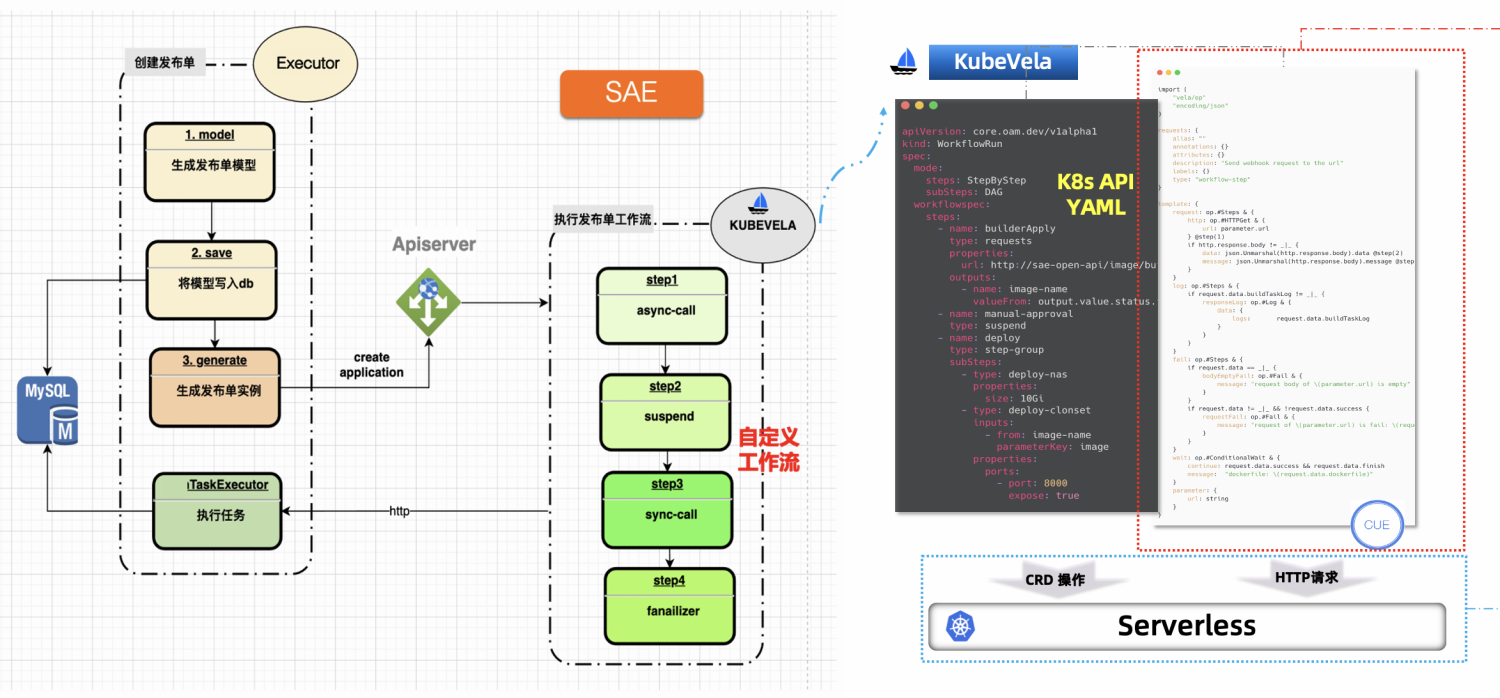
在借助了 KubeVela Workflow 的高可扩展性后,SAE 的工程师既不需要将原有的能力重新打包成镜像,也不需要进行大规模的修改。
新的流程如上图:SAE 产品侧创建了发布单之后,业务侧会将模型写入数据库,进行模型转换,生成一条 KubeVela Workflow,这里对应到右侧的 YAML。
同时,SAE 原本的 JAVA Executor 将原本的业务能力提供成微服务 API。KubeVela Workflow 在执行时,每个步骤都是 IaC 化的,底层实现是 CUE 语言。这些步骤有的会去调用 SAE 的业务微服务 API,有的则会直接与底层 Kubernetes 资源进行交付。而步骤间也可以进行数据传递。如果调用出错了,可以通过步骤的条件判断,来进行错误处理。
这样一种优化,不仅可扩展,充分复用 K8S 生态,工作流流程和原子能力均可扩展,并且面向终态。这种可扩展和流程控制的相结合,能够覆盖原本的业务功能,并且减少开发量。同时,状态的更新从分支级延迟降低到毫秒级,敏捷且原生,不仅具备了 YAML 级的描述能力,还能将开发效率从 1d 提升到 1h。
案例 3:快速上线新功能
除了自动化运维和升级原本的架构,KubeVela Workflow 还能提供什么?
步骤的可复用性和与其他生态的易对接性,在升级之外,给 SAE 带来了额外的惊喜:从编写业务代码变为编排不同步骤,从而快速上线产品的新功能!
SAE 沉淀了大量的 JAVA 基础,并且支持了丰富的功能,如:支持 JAVA 微服务的单批发布,分批发布,以及金丝雀发布等等。但随着客户增多,一些客户提出了新的需求,他们希望能有多语言南北流量的灰度发布能力。
在云原生蓬勃的生态下,灰度发布这块也有许多成熟的开源产品,比如 Kruise Rollout。SAE 的工程师调研后发现,可以使用 Kruise Rollout 来完成灰度发布的能力,同时,配合上阿里云的内部的 ingress controller,ALB,来进行不同流量的切分。
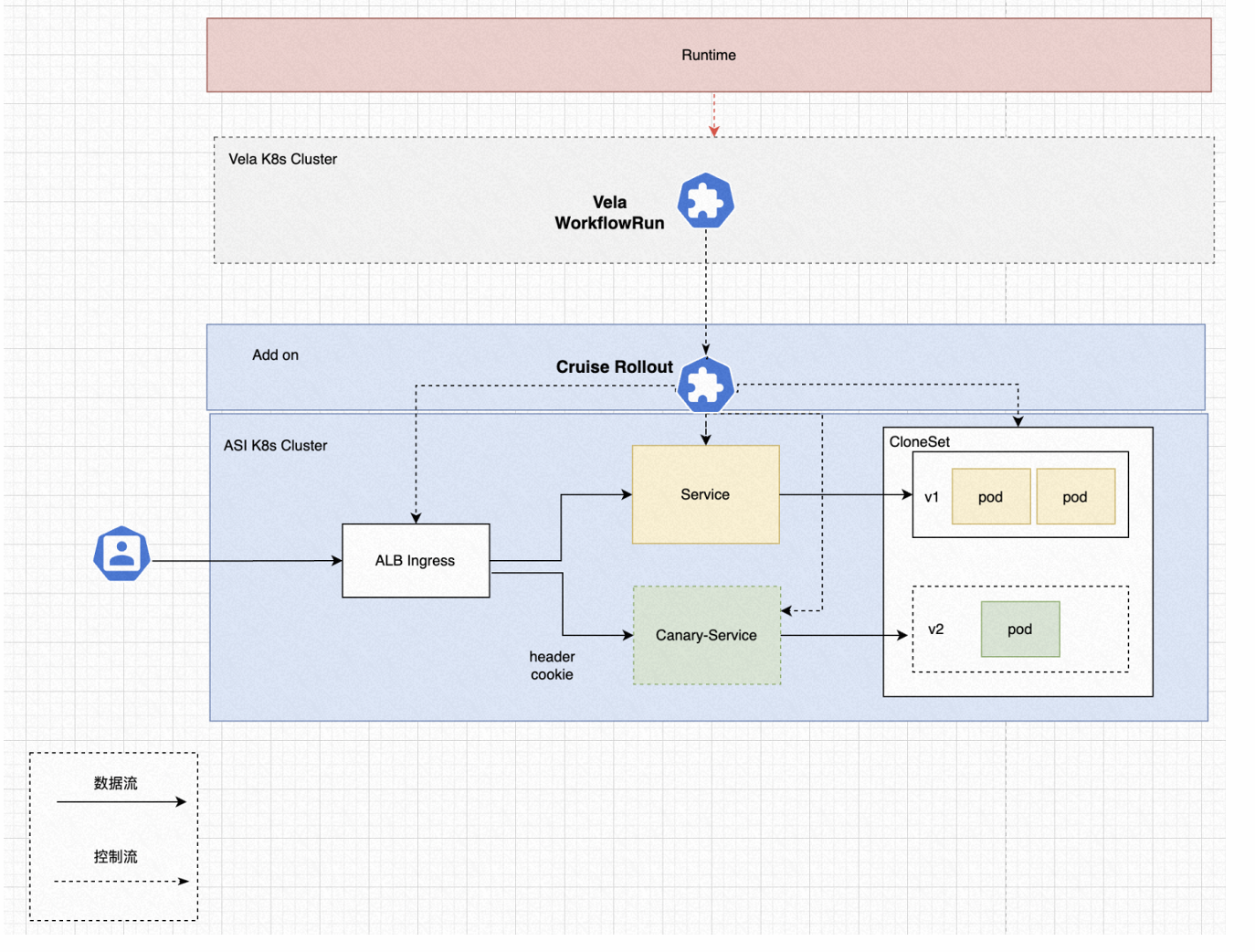
这样一种方案就沉淀成了上面这张架构图,SAE 下发一条 KubeVela Workflow,Workflow 中的步骤将同时对接阿里云的 ALB,开源的 Kruise Rollout 以及 SAE 自己的业务组件,并在步骤中完成对批次的管理,从而完成功能的快速上线。
事实上,使用了 KubeVela Workflow 后,上线这个功能就不再需要编写新的业务代码,只需要编写一个更新灰度批次的步骤类型。
由于步骤类型的可编程性,我们可以轻松在定义中使用不同的更新策略来更新 Rollout 对象的发布批次以及对应下发集群。并且,在工作流中,每个步骤的步骤类型都是可复用的。这也意味着,当你开发新步骤类型时,你也在为下一次,下下次的新功能上线打下了基础。这种复用,可以让你迅速地沉淀功能,极大减少了开发成本。
有了这种高效的编排能力,我们就能进行快速变更,在通用变更的基础上,如果某客户需要开启功能,可以迅速进行自定义变更。
总结
在 SAE 进行了 KubeVela 架构升级后,不仅提升了发布效率,同时,也降低了开发成本。可以在底层依赖 Serverless 基础设施的优势之上,充分发挥产品在应用托管上的优势。
并且,KubeVela Workflow 在 SAE 中的架构升级方案,也是一个可复制的开源解决方案。社区已经内置提供了 50+ 的步骤类型,包括构建、推送镜像,镜像扫描,多集群部署,使用 Terraform 管理基础设施,条件等待,消息通知等,能够帮你轻松打通 CICD 的全链路。
你还可以参考以下文档来获取更多使用场景: