大家好,我是刘俊余(GitHub: iyear),目前就读于软件工程专业大二。在这篇博客中,我将分享我作为 Linux Foundation Mentoship 学员的一些经历:从申请项目到成为社区的一份子。
我在 2023 年春季通过 LFX Mentoship 被选为 CNCF 基金会下 KubeVela 项目的学员,在该项目中,我负责从零开发基于 Golang 的 CUE 代码及文档生成器,为 KubeVela 的未来扩展性铺垫基础设施部分。
什么是 LFX Mentorship?

LFX Mentorship 是一个远程的学习项目,它为开源贡献者提供 12 周的学习机会,由特定的导师(他们通常是项目的主要维护者),帮助学员为社区和项目做出贡献。
许多开源组织或基金会都会通过 LFX Mentorship 为旗下项目发布项目并招募学员进行开发和贡献。我主要关注并工作在云原生领域,在今年二月份关注到 CNCF 在 LFX 上开始了 2023 年春季项目,我开始尝试申请自己感兴趣的项目。
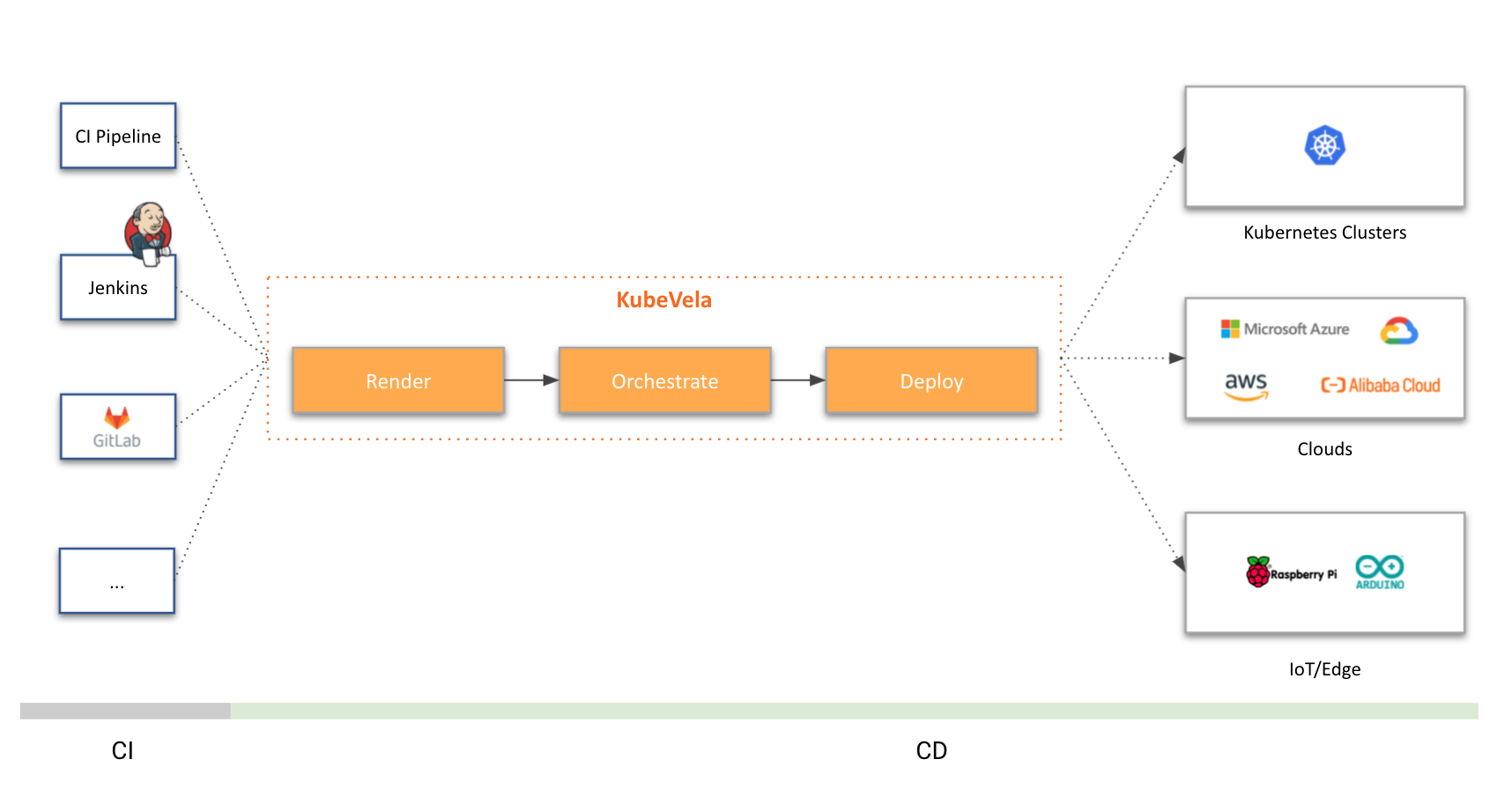
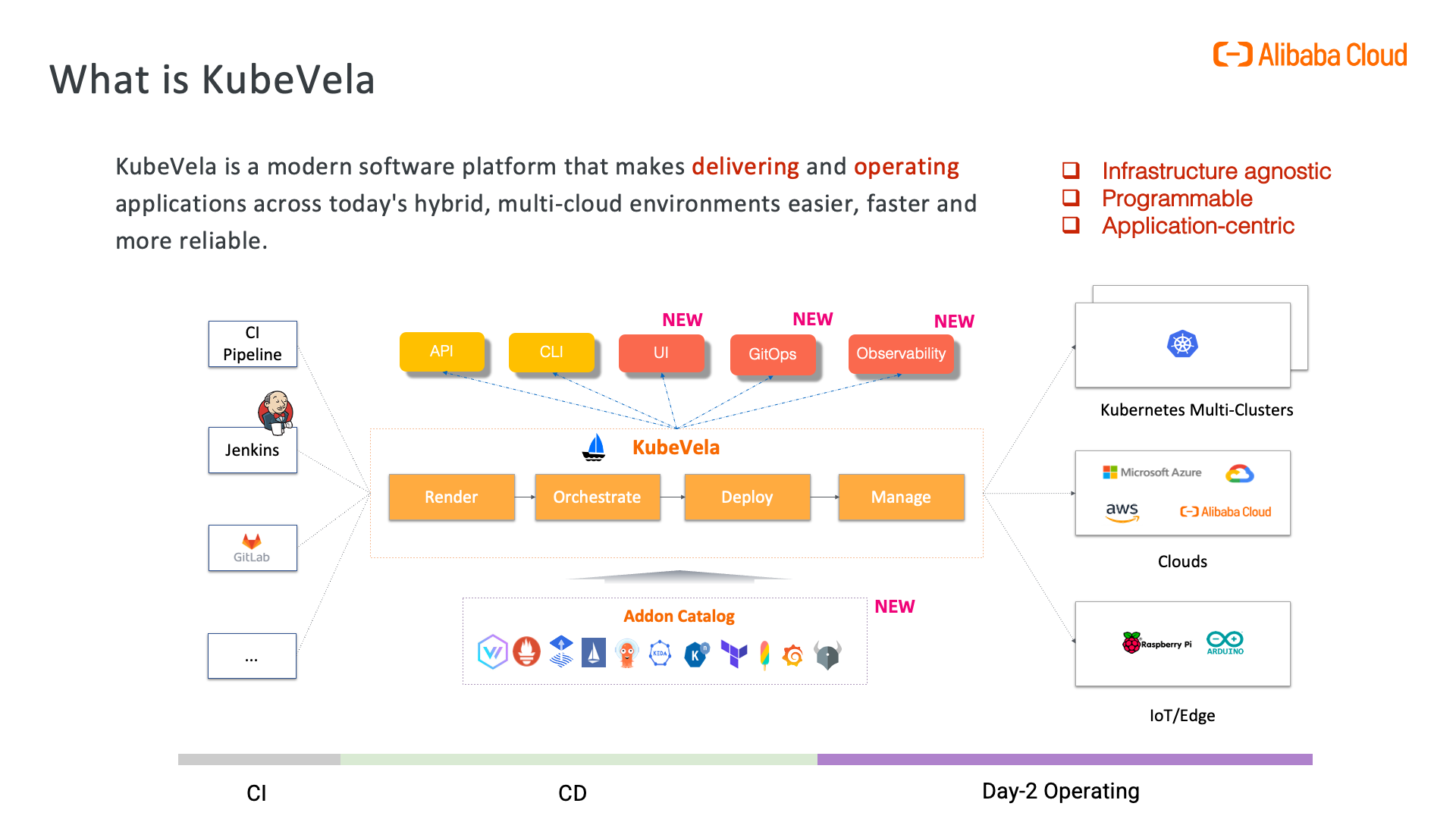
什么是 KubeVela?
![]()
KubeVela 是一个开箱即用的现代化应用交付与管理平台,它使得应用在面向混合云环境中的交付更简单、快捷。
KubeVela 诞生自 2019 年年底阿里云联合微软共同推出的 Open Application Model(简称 OAM )模型基于 Kubernetes 的实现,在不断演进和迭代中融合了大量来自开源社区(尤其是微软、字节跳动、第四范式、腾讯和满帮集团的社区参与者们)的反馈与贡献,最终在 2020 年 KubeCon 北美峰会上以“KubeVela”的名字正式与开源社区见面。
KubeVela 项目发展迅速,其发展里程如下:
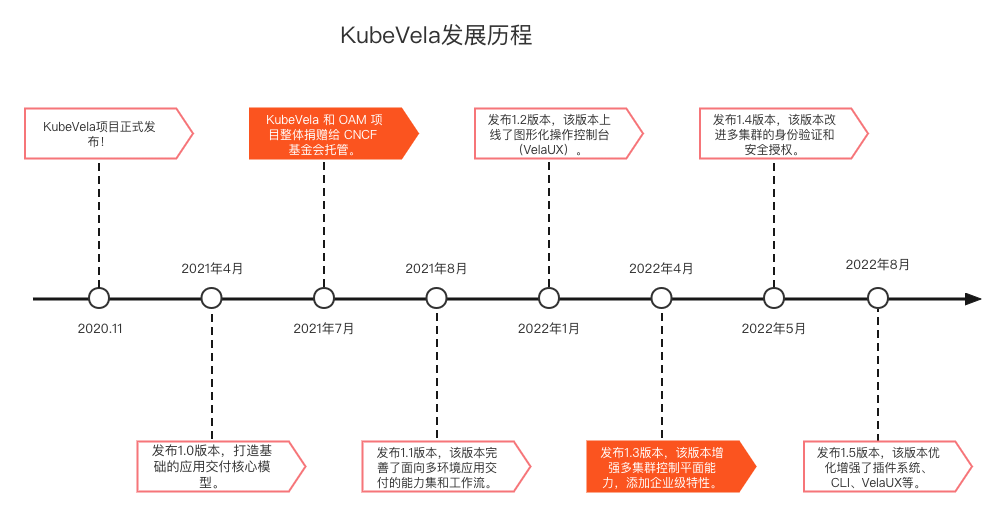
更值得一提的是,在今年3月,KubeVela 晋升为 CNCF 孵化项目,进一步证明了 KubeVela 在生产环境中的稳定性和灵活性。
项目详情
项目名称: Support auto generation of CUE schema and docs from Go struct
项目描述: In KubeVela's provider system, we can use our defined Go functions in CUE schema. The Go providers usually have a parameter and return. Fields in Go providers are the same as fields in CUE schema, so it is possible and important to support automatic generation of CUE schemas and documents from Go structs.
项目要求: Auto-generators of CUE schemas and docs from Go structs, the capabilities should be wrapped in vela cli command.
项目链接: https://mentorship.lfx.linuxfoundation.org/project/85f61cae-02d7-4931-8d87-d3da3128060e
申请及开发过程
在初步浏览项目列表时,KubeVela 就成为了我的候选项之一。在初步探索云原生领域之前我了解过 KubeVela 项目并尝试理解其理念和工作方式,但由于水平有限也便浅尝辄止。而这次如果能通过一个小的切入点最终熟悉 KubeVela 便是最好的贡献路径。同时元编程和代码生成是 Golang 的重要手段,我也想将此项目作为一次实践的机会。
项目涉及到 KubeVela 的核心部分:CUE。这是我第一时间需要去了解的部分,通过 KubeVela 官方文档 和 CUE Issues 我认识到 CUE 是一个为配置而生的语言,在可编程、自动化、Golang 集成度方面都有着其他语言不可比拟的优势,另一方面 KubeVela 在演进的过程中也不断为 CUE 提供实践案例和使用反馈。
在联系导师后,我的目标是先完成一个 DEMO 作为演示。整个项目的核心部分在于 Golang AST 和 CUE AST 的互转,我首先在 CUE 源代码中找到了一部分可以借鉴的代码,读通读懂后提取了核心部分并进行了修改和适配,实现了 DEMO 的结构体转换。
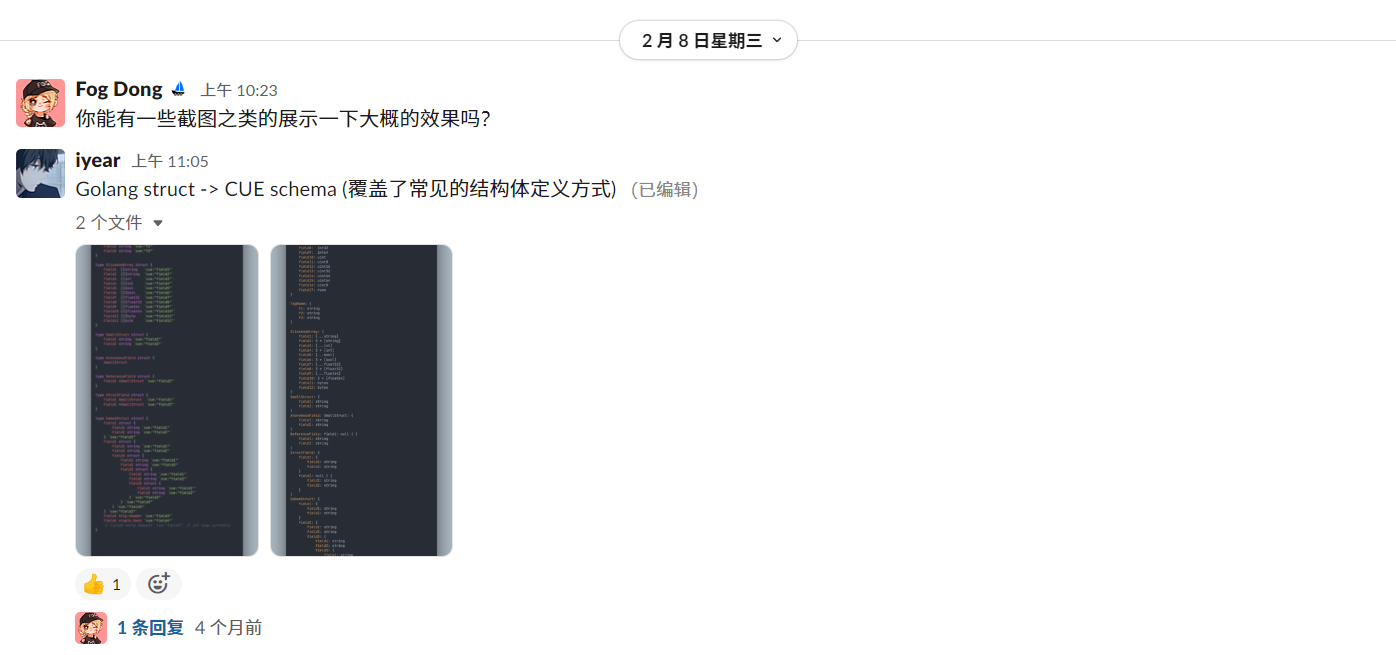
通过 DEMO 的编写,我对整体项目的目标有了更清晰的认知。CUE 作为面向用户和平台开发者的顶层语言,通过 Golang 作为中间媒介与云平台连接、控制,必然会出现大量的 CUE 与 Golang 的交互和转换。在许多场景中,CUE 需要与 Golang 代码保持维护一致性,否则将出现中间转换的错误。
这一过程耗时耗力且只在运行时出现问题,严重时可能会影响生产环境稳定性。这一项目即旨在解决该问题,使 Golang 代码作为单一事实来源,通过静态生成方式保持整体配置的一致性。
在项目描述的 Issue 中,导师以 provider 为例提供了生成预期。结合项目产出后一切都明朗了起来:
我将 CUE Generator 分为三层,最底层负责基础且核心的 AST 转换;中间层负责读取具体的 Golang 代码,例如 provider、policy,将 Golang 代码中的信息提取并写入 CUE 文件中;最上层即将生成能力以 CLI 形式暴露给用户和开发者,能够快捷地生成 CUE 和文档。在未来支持更多不同格式的 CUE 时,可以方便地复用底层转换能力。
在和导师进行了进一步沟通后,我对结构体 Tag 和注释做了进一步支持,并将一些想法总结为提案。在一系列的迭代和沟通后,项目已经初步成型,同时也非常荣幸地被成为 LFX Mentorship 的学员。

经过初期的交流和 DEMO 编写,正式开发的过程整体也比较顺畅,大多数沟通主要在用户体验和细节设计上。第一个 PR 由于没有拆分,收到了许多有价值的 review,经过了 50 个评论才最终合并。由于初期代码来自 DEMO 写的较为随意,最后一段时间也重点重构了部分代码,使代码更加清晰健壮。
自二月第一个 PR 到五月结项的第十五个 PR,项目基本完结且代码全部并入主分支。同时也通过了两次导师评估,即将从 LFX Mentorship 的第一个项目毕业👏
项目产出
近三个月的开发,项目主要产出了三个能力和两个 CLI 用户接口,所有代码测试覆盖率均达到 90% 以上。
项目核心能力处于 references/cuegen 目录下,实现了从 Go AST 转换到 CUE AST 的基础能力,并配以 README 文档供开发者了解具体转换规则。中间层的代码放置于 references/cuegen/generators 目录下,目前已经实现了针对 provider 格式的生成器。文档生成部分位于 references/docgen/provider.go ,复用了 docgen 的能力为 CUE 自动生成文档。
项目增加了两个 CLI 子命令,分别为 vela def gen-cue 与 vela def gen-doc。前者将 Golang 代码生成为对应格式的 CUE 文件,即将中间层能力暴露为 CLI 接口,后者将 CUE 生成为对应的文档。
由于 vela def gen-cue 单次只支持一个文件,通过编写 Shell 脚本为其实现了遍历目录批量生成的功能:#6009
以 kubevela/pkg/providers/kube 的代码片段为例,进行改造与验证。
先将 kube.go 转换为 kube.cue :
$ vela def gen-cue \
-t provider \
--types *k8s.io/apimachinery/pkg/apis/meta/v1/unstructured.Unstructured=ellipsis \
--types *k8s.io/apimachinery/pkg/apis/meta/v1/unstructured.UnstructuredList=ellipsis \
kube.go > kube.cue
再将 kube.cue 转换为 kube.md
$ vela def gen-doc -t provider kube.cue > kube.md
最终效果如下:

未来展望
虽然本次 LFX Mentorship 的期望产出已经全部实现,但这只是 cuegen 的第一步,其衍生工作对 KubeVela 的未来发展也将起到重要作用。
例如,基于 cuegen 我们可以对当前依赖手工维护的 policy 规则进行自动生成化改造;对 kubevela/pkg 中已有的 providers 进行迁移和验证;对用户自定义 provider 的脚手架生成工具等等都需要依赖于 cuegen 的转换能力。这也是我未来在社区工作的重点方向。
除了 cuegen 生态的相关工作,我也将深入 KubeVela 的其他方面,比如对 OAM 生产实践和用户社群的熟悉深入、阅读 Workflow 组件源码探索新特性的可能性……我也发起了对 KubeVela Reviewer 的申请,尝试为项目代码质量控制做出一些贡献。
这是我第一次参加 LFX Mentorship 项目,在为期三个月的沟通和交流中,两位导师在细节和决策上都给予了我许多帮助和指导,结项前我们也通过线上 Meeting 完整演示了功能、讨论了未来社区的工作方向和规划。
开源是一个兴趣主导,自驱力推动的过程。开发者能在不同社区工作的经历中不断提高自己,与社区共同成长。开源就是对有兴趣的项目都应该勇于迈出第一步,去尝试读一读项目的源码。学生参与开源更多的是一个学习的过程,在开源道路上的每一步都会有不同的收获和感悟。非常感谢能在 LFX Mentorship 与 KubeVela 社区相遇,期待未来对社区的进一步深入和贡献!