The Canary Rollout of the Helm Chart Application Is Coming!
Background
Helm is an application packaging and deployment tool of client side widely used in the cloud-native field. Its simple design and easy-to-use features have been recognized by users and formed its ecosystem. Up to now, thousands applications have been packaged using Helm Chart. Helm's design concept is very concise and can be summarized in the following two aspects:
-
Packaging and templating complex Kubernetes APIs and then abstracting and simplifying them into small number of parameters
-
Giving Application Lifecycle Solutions: Production, upload (hosting), versioning, distribution (discovery), and deployment.
These two design principles ensure that Helm is flexible and simple enough to cover all Kubernetes APIs, which solves the problem of one-off cloud-native application delivery. However, for enterprises with a certain scale, using Helm for continuous software delivery poses quite a challenge.
Challenges of the Continuous Delivery of Helm
Helm was initially designed to ensure simplicity and ease of use instead of complex component orchestration. Therefore, Helm delivers all resources to Kubernetes clusters during the application deployment. It is expected to solve application dependency and orchestration problems automatically using Kubernetes' final-state oriented self-healing capabilities. Such a design may not be a problem during its first deployment, but it is too idealistic for the enterprise with a certain scale of production environment.
On the one hand, updating all resources when the application is upgraded may easily cause overall service interruption due to the short-term unavailability of some services. On the other hand, if there is a bug in the software, it cannot be rolled back in time, which may cause more trouble and make it difficult to control. In some serious scenarios, if some configurations in the production environment have been manually modified in O&M, the original modifications would be overwritten due to the one-off deployment of Helm. What's more, the previous versions of Helm may be inconsistent with the production environment, so it cannot be recovered using rollback. All of these add up to a larger area of failure.
Thus, with a certain scale, the grayscale and rollback capabilities of the software in the production environment are extremely important, and Helm itself cannot guarantee sufficient stability.
How Do We Enable Canary-Rollout for Helm?
Typically, a rigorous software upgrade process follows a similar process: It is roughly divided into three stages. The first stage upgrades small number of pods (such as 20% ) and switches a small amount of traffic to the new version. After completing this stage, the upgrade is paused first. After manual confirmation, continue the second phase, which is to upgrade a larger proportion of pods and traffic (such as 90% ), and pause again for manual confirmation. In the final stage, the full upgrade to the new version is completed, and the verification is completed, thus the entire rollout process is completed. If any exceptions, including business metrics, are found during the upgrade, such as an increase in the CPU or memory usage rate or excessive log requests error 500, you can roll back quickly.
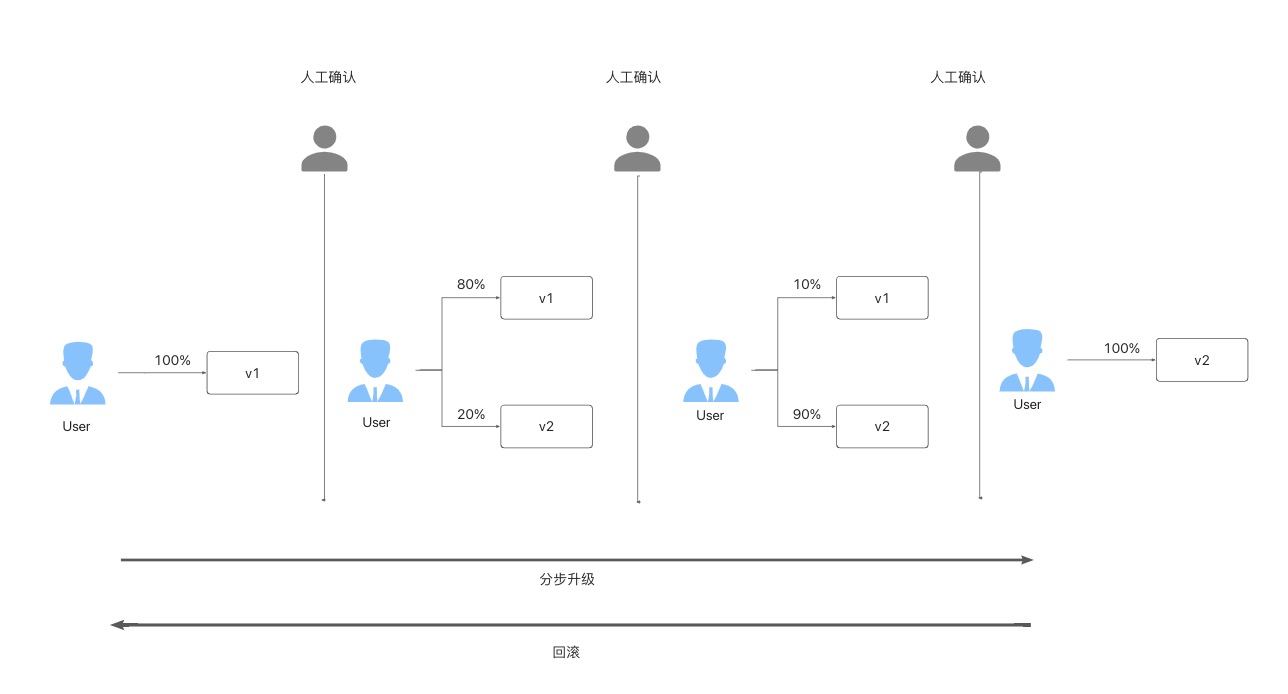
The image above is a typical canary rollout scenario, so how do we complete the above process for the Helm chart application? There are two typical ways in the industry:
- Modify the Helm chart to change workloads into two copies and expose different Helm parameters. During the rollout, the images, number of pods, and traffic ratio of the two workloads are continuously modified to implement the canary rollout.
- Modify the Helm chart to change the original basic workload to a custom workload with the same features and with phased rollout capabilities and expose the Helm parameters. It's these canary rollout CRDs that are manipulated during the canary rollout.
The two solutions are complex with considerable modification costs, especially when your Helm chart is a third-party component that cannot be modified or cannot maintain a Helm chart. Even if the two are modified, there are still stability risks compared to the original simple workload model. The reason is that Helm is only a package management tool, and it is incompatible with the canary rollout or workloads management.
When we have in-depth communication with large number of users in the community, we find that most users' applications are not complicated, among which the most are classic types (such as Deployment and StatefulSet). Therefore, through the powerful addon mechanism of KubeVela and the OpenKruise community, we have made a canary rollout KubeVela Addon for these qualified types. This addon helps you easily complete the canary rollout of the Helm chart without any migration and modification. Also, if your Helm chart is more complicated, you can customize an addon for your scenario to get the same experience. Let's take you through a practical example (using Deployment Workload as an example) to get a glimpse of the complete process.
Use KubeVela for Canary Rollout
Prepare the Environment
- Install KubeVela
$ curl -fsSL https://kubevela.io/script/install-velad.sh | bash
velad install
See this document for more installation details.
- Enable related addon
vela addon enable fluxcd
vela addon enable ingress-nginx
vela addon enable kruise-rollout
vela addon enable velaux
In this step, the following addons are started:
- The fluxcd addon helps us enable the capability of Helm delivery.
- The ingress-nginx addon is used to provide traffic management capabilities of canary rollout.
- The kruise-rollout provides canary rollout capability.
- The velaux addon provides interface operation and visualization.
- Map the Nginx ingress-controller port to local
vela port-forward addon-ingress-nginx -n vela-system
First Deployment
Run the following command to deploy the Helm application for the first time. In this step, the deployment is done through KubeVela's CLI tool. If you are familiar with Kubernetes, you can also deploy through kubectl apply. The two work the same.
cat <<EOF | vela up -f -
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: canary-demo
annotations:
app.oam.dev/publishVersion: v1
spec:
components:
- name: canary-demo
type: helm
properties:
repoType: "helm"
url: "https://wangyikewxgm.github.io/my-charts/"
chart: "canary-demo"
version: "1.0.0"
traits:
- type: kruise-rollout
properties:
canary:
# The first batch of Canary releases 20% Pods, and 20% traffic imported to the new version, require manual confirmation before subsequent releases are completed
steps:
- weight: 20
# The second batch of Canary releases 90% Pods, and 90% traffic imported to the new version.
- weight: 90
trafficRoutings:
- type: nginx
EOF
In the example above, we declare an application named canary-demo, which contains a Helm-type component (KubeVela also supports other types of component deployment), and the parameter of the component contains information (such as chart address and version).
In addition, we declare the kruise-rollout OAM trait for this component, which are the capabilities added to the component after the kruise-rollout addon is installed. The upgrade policy of Helm can be specified. In the first stage, 20% of pods and traffic are upgraded. After manual approve, 90% is upgraded. Finally, the full version is upgraded to the latest version.
Note: We have prepared a chart to demonstrate the intuitive effect (reflecting the version changes). The body of the Helm chart contains a Deployment and Ingress object, which is the most common scenario when the Helm chart is made. If your Helm chart is also equipped with the resources above, you can also use this example to canary rollout your helm chart.
After the deployment is successful, we use the following command to access the gateway address in your cluster, and you will see the following result:
$ curl -H "Host: canary-demo.com" http://localhost:8080/version
Demo: V1
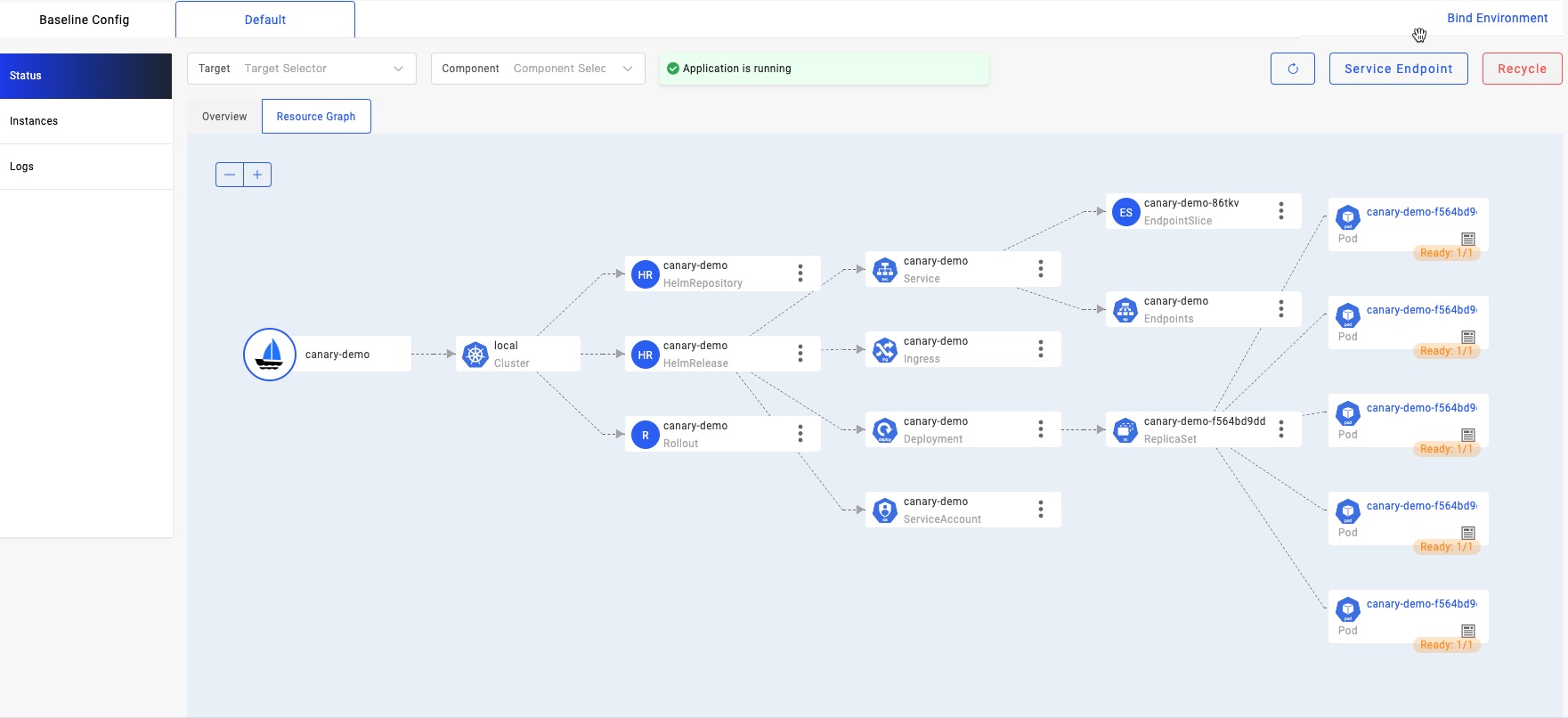
In addition, through the resource topology graph of VelaUX, we can see that the five V1 pods are all ready.
Upgrade an Application
Apply the following yaml to upgrade your application:
cat <<EOF | vela up -f -
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: canary-demo
annotations:
app.oam.dev/publishVersion: v2
spec:
components:
- name: canary-demo
type: helm
properties:
repoType: "helm"
url: "https://wangyikewxgm.github.io/my-charts/"
chart: "canary-demo"
# Upgade to version 2.0.0
version: "2.0.0"
traits:
- type: kruise-rollout
properties:
canary:
# The first batch of Canary releases 20% Pods, and 20% traffic imported to the new version, require manual confirmation before subsequent releases are completed
steps:
- weight: 20
# The second batch of Canary releases 90% Pods, and 90% traffic imported to the new version.
- weight: 90
trafficRoutings:
- type: nginx
EOF
We noticed that the new application only has two changes compared to the first deployment:
-
We upgrade the annotation of the app.oam.dev/publishVersion from V1 to V2. This shows this revision is a new version.
-
We upgrade the version of the Helm chart to 2.0.0. The tag of the deployment image in this version of the chart is upgraded to V2.
After a while, we will find that the upgrade process stops at the first batch we defined above. Only 20% of pods and traffic are upgraded. At this time, if you execute the command above to access the gateway multiple times, you will find that Demo: V1 and Demo: V2 appear alternately, and there is a probability of almost 20% of getting the result of Demo: V2.
$ curl -H "Host: canary-demo.com" http://localhost:8080/version
Demo: V2
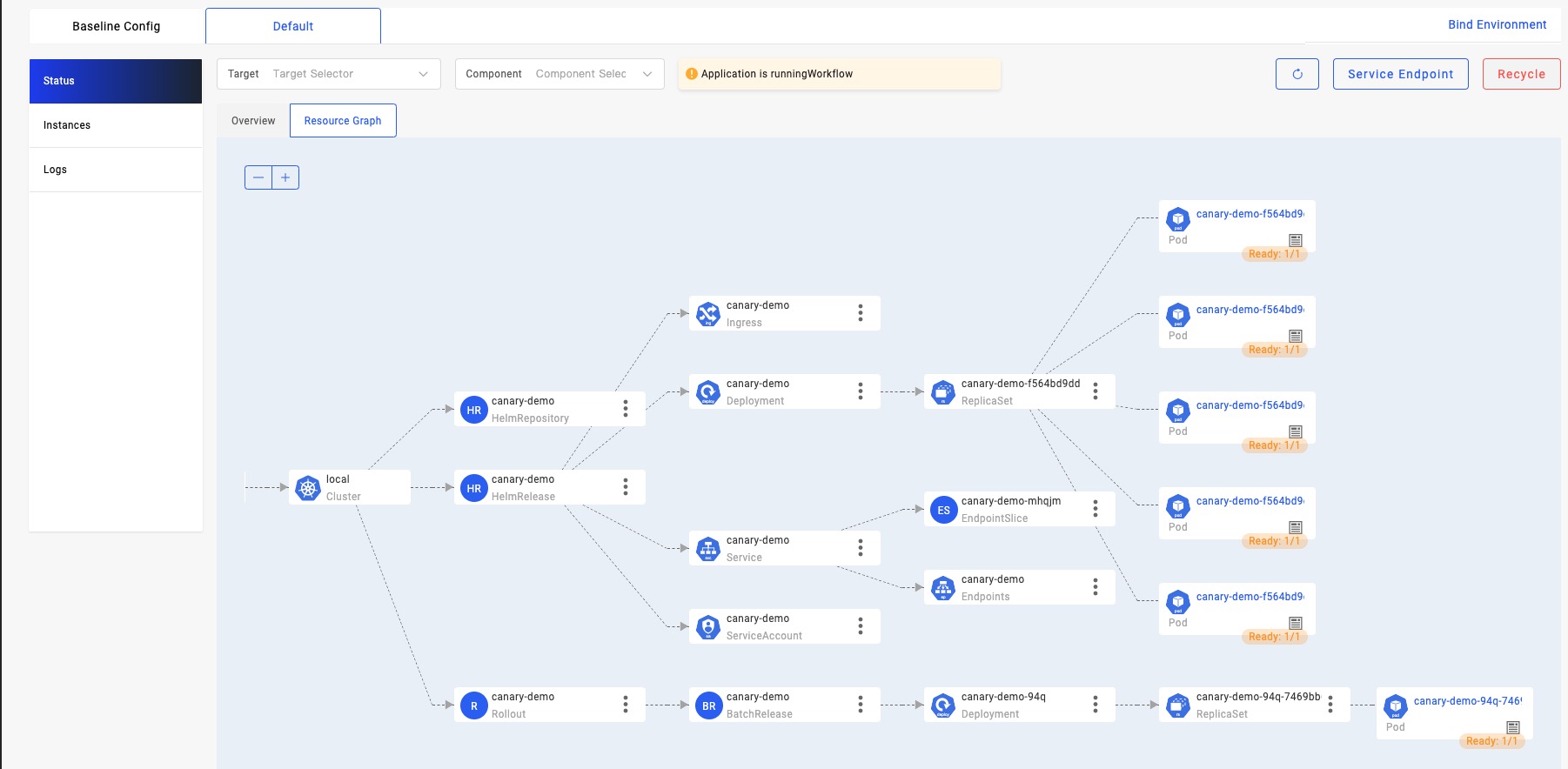
Looking at the topology status of the application resources again, you will see that the rollout CR created by the kruise-rollout trait has created a new version of the pod for us, while the five old version pods created by the previous workload remain unchanged.
Next, we execute the following command through KubeVela's CLI to resume the upgrade through manual review:
$ vela workflow resume canary-demo
After a while, we saw that five new versions of pods were created through the resource topology diagram. At this time, if we visit the gateway again, we will find that the probability of Demo: V2 has increased significantly, which is close to 90%.
Quick Rollback
Generally, in the rollout of a real-world scenario, after a manual review, it is found that the status of the new version of the application is abnormal. You need to terminate the current upgrade and quickly roll back the application to the version before the upgrade starts.
We can execute the following command to suspend the current publishing workflow first:
$ vela workflow suspend canary-demo
Rollout default/canary-demo in cluster suspended.
Successfully suspend workflow: canary-demo
Then, roll back to the version before the rollout, which is V1:
$ vela workflow rollback canary-demo
Application spec rollback successfully.
Application status rollback successfully.
Rollout default/canary-demo in cluster rollback.
Successfully rollback rolloutApplication outdated revision cleaned up.
At this time, when we access the gateway again, we will find that all the request results have returned to the V1 state:
$ curl -H "Host: canary-demo.com" http://localhost:8080/version
Demo: V1
At this time, we can see that all pods of the canary version have been deleted through the resource topology diagram, and from the beginning to the end, the five pods of V1, as the pods of the stable version, remain unchanged.
If you change the rollback operation above to resume the upgrade, the subsequent upgrade process will continue to complete the full rollout.
Please see this link for the complete operation procedure of the preceding demo.
Please refer to this link if you want to directly use native Kubernetes resources to implement the process above.
In addition to Deployment, the kruise-rollout addon supports StatefulSet and OpenKruise CloneSet. If the workload types in your chart are one of the three types mentioned above, canary rollout can be implemented through the example above.
I believe you can also notice that the example above is a nginx-Ingress-controller-based seven-layer traffic splitting scheme. In addition, we support Kubernetes Gateway's API to support more gateway types and four-layer traffic splitting schemes.
How Can the Stability of the Rollout Be Guaranteed?
After the first deployment, the kruise rollout addon (hereinafter referred to as rollout) listens to the resources deployed by the Helm chart, which are deployment, service, and ingress in the example. StatefulSet and OpenKruise Cloneset are also supported. The rollout will take over the subsequent upgrade actions of this deployment.
During the upgrade, the new version of Helm takes effect first, and the deployment image is updated to V2. However, the upgrade process of the deployment will be taken over by the rollout process from the controller-manager, so the pods under the deployment will not be upgraded. At the same time, the rollout will copy a canary version of deployment, with V2 as the tag of the image, and create a service to filter the pods below it, together with an ingress pointing to this service. Finally, this ingress will receive the traffic of the canary version by setting the annotation corresponding to the ingress, thus enabling traffic splitting. For details, Please see this link.
After all manual confirmation steps are passed, and the full rollout is completed, the rollout will return the upgrade control of deployment of the stable version to the controller-manager. At that time, the stable version of pods will be upgraded to the new version one after another. When the stable version pods are all ready, the canary version of deployment, service, and ingress will be destroyed one after another, thus ensuring that the request traffic will not hit the unready pod during the whole process nor cause abnormal requests.
After that, we will continue to iterate in the following areas to support more scenarios and bring a more stable and reliable upgrade experience:
- The upgrade process is connected to KubeVela's workflow system, thus introducing a richer system of intermediate steps to expand the system and supporting functions (such as sending notifications through the workflow during the upgrade process). Even in the pause phase of each step, it can connect to the external observability system and automatically decide whether to continue publishing or roll back by checking indicators (such as logs or monitoring) to implement unattended publishing policies.
- It integrates with more addons (such as istio) to support the traffic splitting solution of Service Mesh.
- In addition to the percentage-based traffic splitting method, header-or cookie-based traffic splitting rules and features (such as blue-green publishing) are supported.
Summary
As mentioned earlier, Helm's canary rollout process is implemented by KubeVela through the addon system. fluxcd addon helps us deploy and manage the lifecycle of the Helm chart. The kruise-rollout addon helps us upgrade the workload pod and switch traffic during the upgrade process. By combining two addons, the full lifecycle management and canary upgrade of Helm applications are realized without any changes to your Helm chart. You can also write addon for your scenarios to complete more special scenes or processes.
Based on KubeVela's powerful scalability, you can flexibly combine these addons and dynamically replace the underlying capabilities according to different platforms or environments without any changes to the upper-level applications. For example, if you prefer to use argocd instead of fluxcd to implement the deployment of Helm applications, you can implement the same function by enabling the addon of argocd without any changes or migration at the upper-layer of Helm applications.
Now, the KubeVela community has provided dozens of addons, which can help the platform expand its capabilities in observability, GitOps, FinOps, rollout, etc.

You can find Addon's warehouse address here. If you are interested in addons, you are welcome to submit your custom addon and contribute new ecological capabilities to the community!