Trace and visualize the relationships between the kubernetes resources with KubeVela

One of the biggest requests from KubeVela community is to provide a transparent delivery process for resources in the application. For example, many users prefer to use Helm Chart to package a lot of complex YAML, but once there is any issue during the deployment, such as the underlying storage can not be provided normally, the associated resources are not created normally, or the underlying configuration is incorrect, etc., even a small problem will be a huge threshold for troubleshooting due to the black box of Helm chart. Especially in the modern hybrid multi-cluster environment, there is a wide range of resources, how to obtain effective information and solve the problem? This can be a very big challenge.
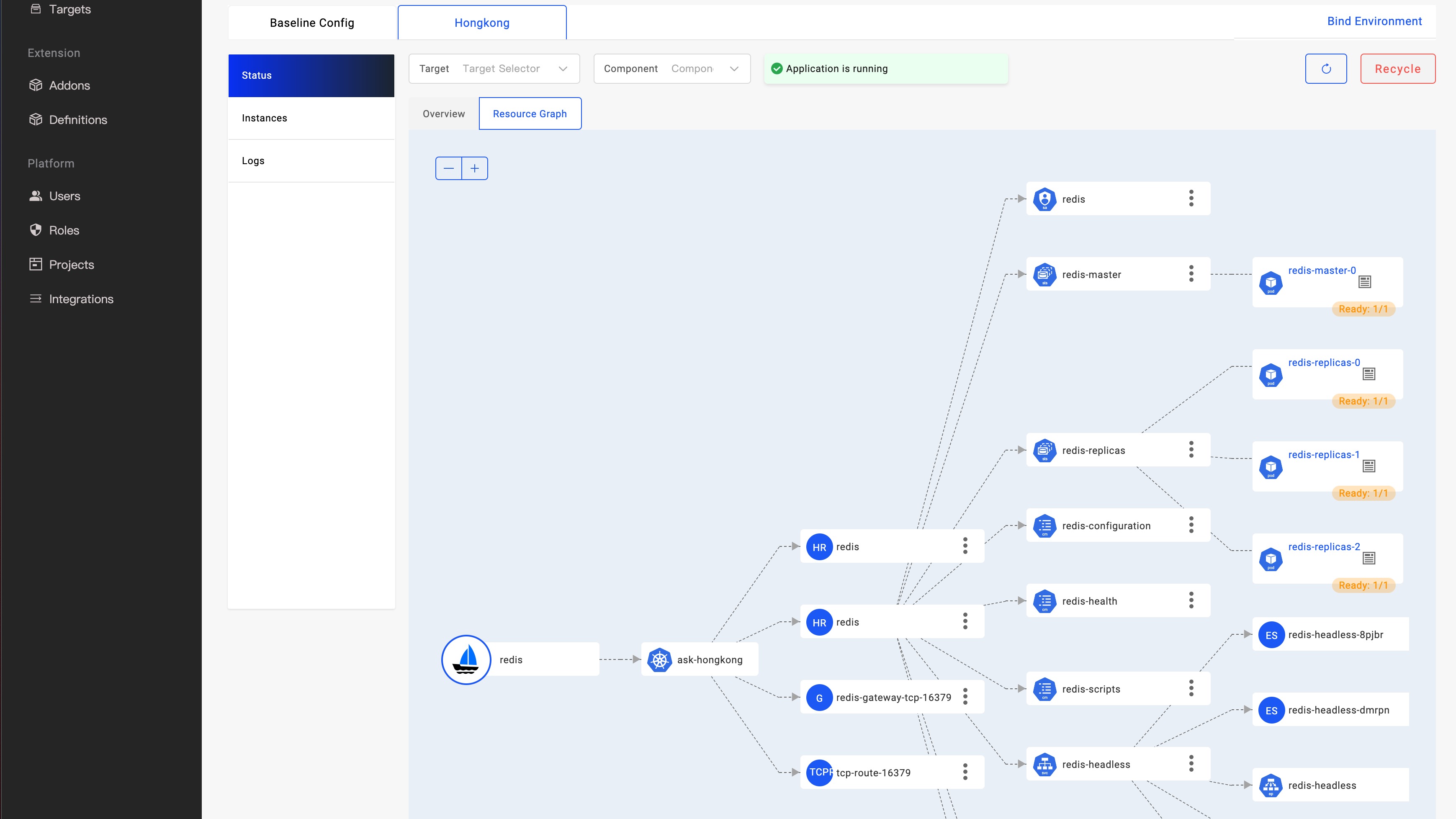
As shown in the figure above, KubeVela has offered a real-time observation resource topology graph for applications, which further improves KubeVela's application-centric delivery experience. Developers only need to care about simple and consistent APIs when initiating application delivery. When they need to troubleshoot problems or pay attention to the delivery process, they can use the resource topology graph to quickly obtain the arrangement relationship of resources in different clusters, from the application to the running status of the Pod instance. Automatically obtain resource relationships, including complex and black-box Helm Charts.
In this post, we will describe how this new feature of KubeVela is implemented and works, and the roadmap for this feature.
Application resource composition
In KubeVela, an application consists of multiple components and traits and is associated with delivery workflow and delivery policy configuration. The application configuration generates Kubernetes resources through rendering and inspection and applies them to the target cluster. Take a simple application as an example:
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: first-vela-app
spec:
components:
- name: express-server
type: webservice
properties:
image: oamdev/hello-world
ports:
- port: 8000
expose: false
Based on the above configuration, a Deployment resource will be rendered and deployed to the target cluster, if we slightly add some configuration, such as:
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: first-vela-app
spec:
components:
- name: express-server
type: webservice
properties:
image: oamdev/hello-world
ports:
- port: 8000
expose: true
traits:
- type: gateway
properties:
domain: testsvc.example.com
http:
"/": 8000
In the above configuration, we set the expose field of port 8000 to true, and add a trait with type gateway. The application will render three resources Deployment + Service + Ingress.
As mentioned above, the resources directly rendered by the application are called Direct Resources, and they will be stored in ResourceTracker as version records at the same time, and these resources can be obtained by direct indexing. When these resources are delivered to the target cluster, taking the Deployment resource as an example, the lower-level resource ReplicaSet will be generated, and then the lower-level resource Pod will be derived. These secondary derived resources from direct resources are called Indirect Resources. An application resource tree consists of direct resources and indirect resources, that work together to run dynamic applications at scale.
Trace and Visualize resources’ relationships
The relationship chain Deployment => ReplicaSet => Pod described in the previous chapter is a resource cascade relationship, which is also the introductory knowledge of the Kubernetes system. We can build this relationship chain very easily through experience. Where Deployment is a direct resource, which we can index to based on (application & component & cluster) conditions. Next, we mainly build the relationship between the indirect resources.
In Kubernetes, the concept of Owner Reference is designed to record the relationship between resources. For example, in the following use case, the Pod resource records its parent resource ReplicaSet.
apiVersion: v1
kind: Pod
metadata:
name: kruise-rollout-controller-manager-696bdb76f8-92rsn
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: kruise-rollout-controller-manager-696bdb76f8
uid: aba76833-b6e3-4231-bf2e-539c81be9278
...
Therefore, we can reversely build any resource-dependent link through the resource's Owner Reference. However, there are two difficulties here:
-
The resource links in our experience may not necessarily be constructed through Owner Reference, such as the HelmRelease resource, which is the resource API defined by FluxCD to deliver the Helm Chart artifacts. In KubeVela, we use this API to deliver Helm Chart artifacts. Helm Chart can theoretically include any Kubernetes cluster resource type. From user experience, these resources are subordinate resources of HelmRelease, but HelmRelease cannot be the owner of these resources at present. That is to say, we cannot build a tracking link similar to the HelmRelease resource through Owner Reference.
-
When forward tracing resources, if you do not know the subordinate resource types, you need to traverse and query all types of resources and then filter them according to the Owner Reference, which results in a large amount of computation and puts a lot of pressure on the Kubernetes API.
The cascading relationship of application resources is often the link when we troubleshoot application failures or configuration errors. If your Kubernetes experience cannot build such a link, it will be very difficult to troubleshoot Kubernetes application failures. For example, HelmRelease, once encountering a failure, maybe we need to check the definition source code of Chart to know which subordinate resources it will generate. This threshold may hinder 90% of developers and users.
There are many types resources that do not follow the Owner Reference in Kubernetes and continue to grow. Therefore, we need to enable the system to have the ability to learn to speed up forward queries and adapt to resources that do not follow the Owner Reference mechanism.
apiVersion: v1
kind: ConfigMap
metadata:
name: clone-set-relation
namespace: vela-system
labels:
"rules.oam.dev/resources": "true"
data:
rules: |-
- parentResourceType:
group: apps.kruise.io
kind: CloneSet
childrenResourceType:
- apiVersion: v1
kind: Pod
The above is a configuration use case that informs KubeVela that the CloneSet resource cascades down the Pod, KubeVela will query the Pod that satisfies the Owner Reference condition from the same Namespace, so that the query complexity is O(1). A rule defines multiple resource types that are associated with a parent type down, this way is called static configuration learning. We need to implement more rules:
For example, if we need to pay attention to whether the Service is correctly associated with the Pod, and whether the PVC is correctly associated with the PV, there is no Owner Reference filter rule between these resources. If only configuring the type is not enough, we also need to have filter conditions, such as through labels, name, etc. At present, this part of the logic of KubeVela has some built-in rules. In addition, to simplify the user's burden of configuring static learning rules, we plan to implement dynamic learning capabilities. Based on all resource types in the current cluster, the system can dynamically analyze a certain type of resource as the owner of which types of resources. The result rules can be shared.
Visualize the resource status and key information
If there is only a resource relationship, it cannot solve our difficulties. We also need to be able to directly reflect exceptions, so that developers can have O(1) complexity when troubleshooting errors. Different resources have slightly different state calculations, but the general resource state has a Condition field that represents its final state. Based on this, the resource state calculation logic is formed by adding the state calculation method of a specific resource. We divide the resource state into normal, in-progress and abnormal, which are represented by blue, yellow and red border colors on the topology graph node, which is convenient for users to distinguish.
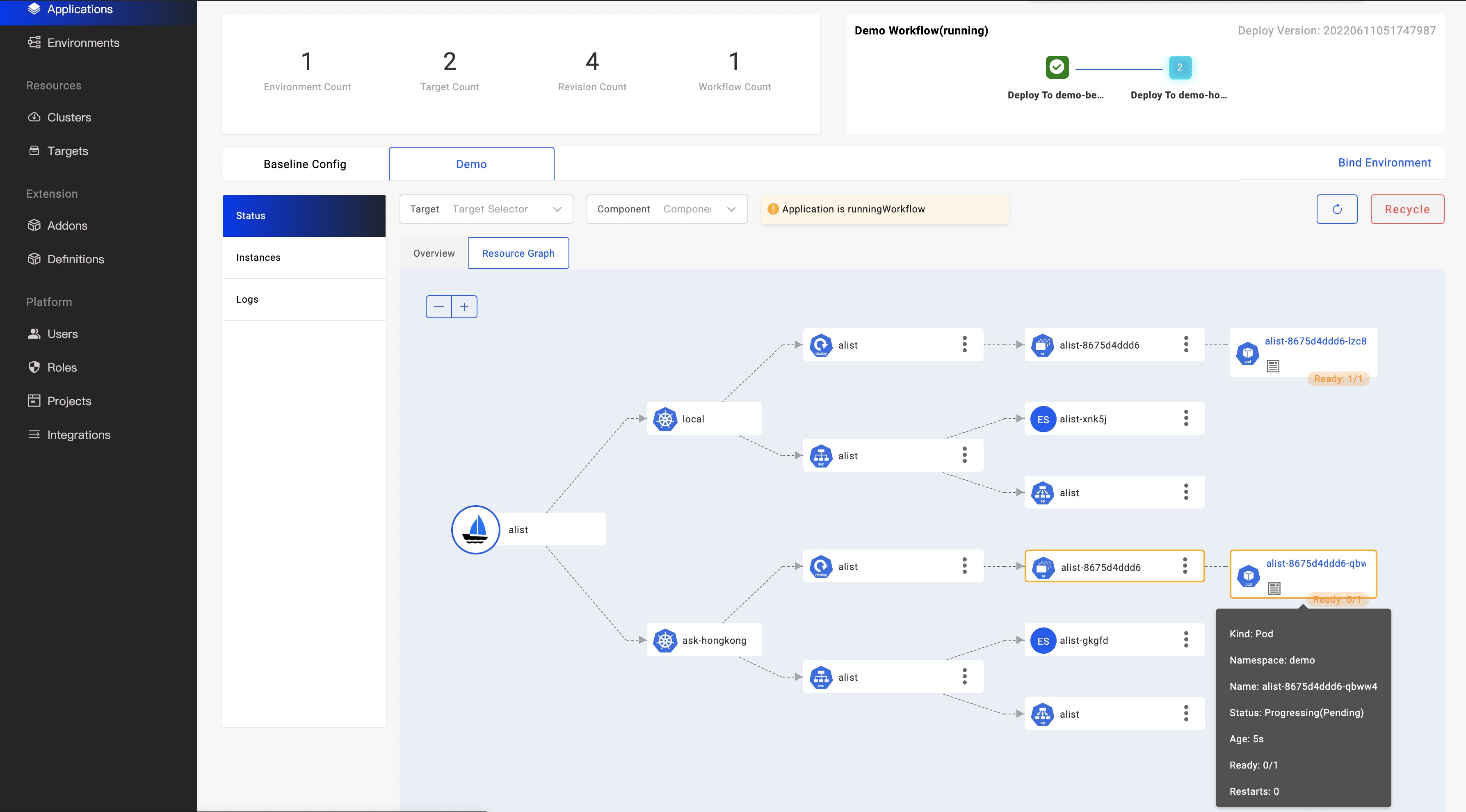
In addition, different resources have different key information, such as whether PVC is bound, whether Pod instance is started, whether Service resource is associated with external IP and so on. These are called key information, and some information is displayed on the resource node bottom, others display when the mouse moves over the node. The information helps you quickly determine whether the resource configuration is correct and its status is normal.
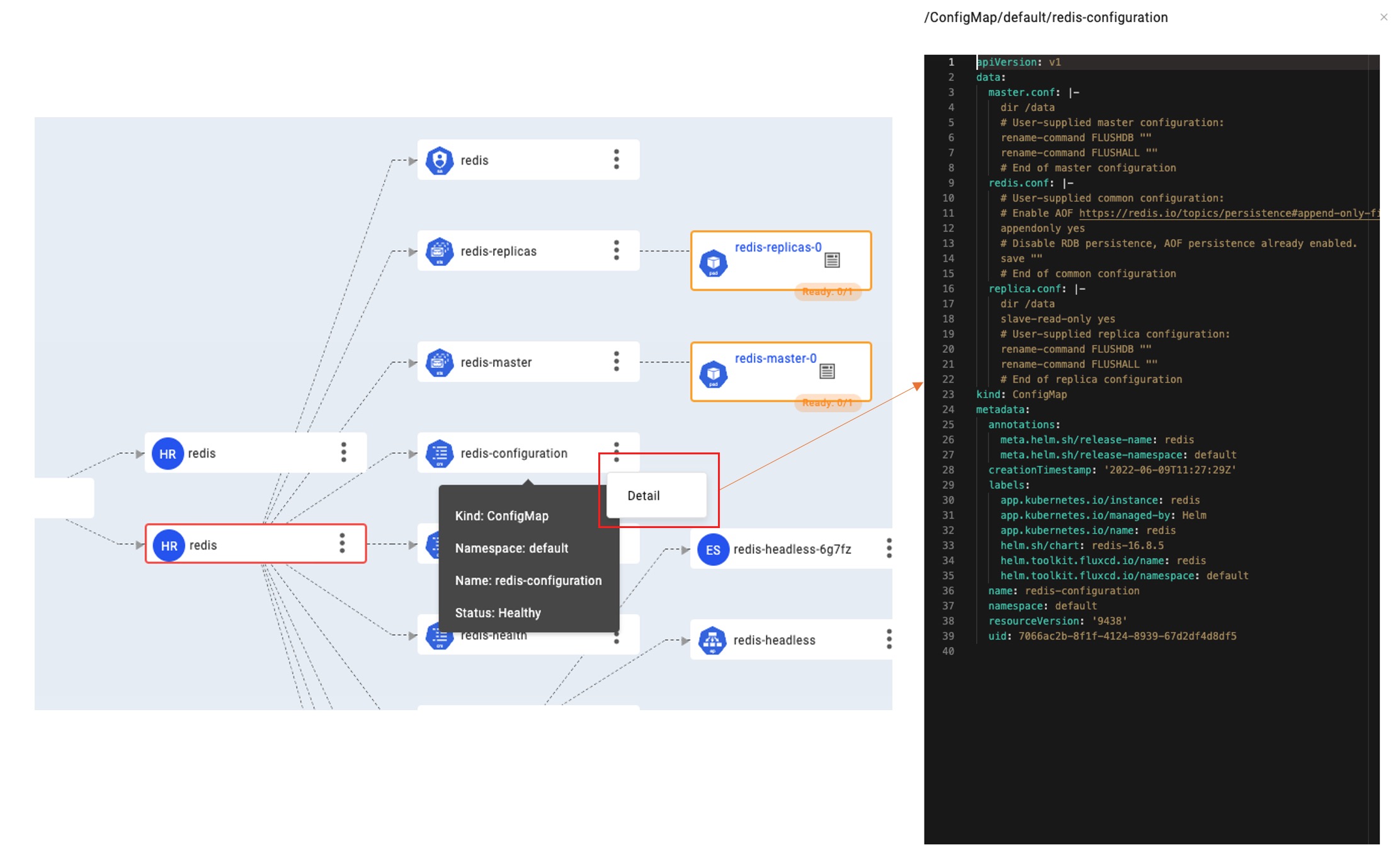
Further, if you want to query the detailed configuration of ConfigMap, whether the capacity and access method of PersistentVolumes are correct, whether the RBAC authorization rules are correct, etc., you do not need to leave the VelaUX and manually dig through YAML files. Initiate a query by clicking the Detail button in the node extension area. KubeVela will securely query and display the latest configurations from the target cluster through the cluster gateway.
What's next?
- More intelligent
We will continue to refine the default rules and find more ways to intelligently judge resource diagrams and key information so that developers can troubleshoot errors without too much experience.
- Application topology graph
What we are currently building is the Kubernetes resource map, which is actually not our original intention. We prefer that business developers only pay attention to the application and all the relationships and states of its components, and at the same time combine business metrics analysis and monitoring data to reflect the operating pressure of the service.
- More runtimes
The currently established resource relationship graph is mainly based on Kubernetes resources. KubeVela also has a core runtime that is a cloud service platform. We need to associate the resource system of cloud services with the resource topology graph. Makes it easier for developers to manage multi-cloud applications.