Modeling AI inference with KubeVela and OAM

AI product work used to be dominated by training: big clusters, rare model releases, and a one-time capital bill. That center of gravity has moved. Once a model ships, the lasting cost is inference: every chat turn, every tool call, every agent loop that keeps the meters running.
Industry analyses put the AI inference market on the order of $100B+ in 2025, with projections toward roughly $255B by 2030 (SoftwareSeni overview of Grand View / MarketsandMarkets figures; directional, not exact). Stanford HAI’s AI Index 2025 documents a collapse in unit price for GPT-3.5-class quality inference, from about $20 per million tokens to roughly $0.07 over a two-year window, while total spend still rose because cheaper tokens unlock more traffic (also summarized in Telnyx’s training vs inference note). Over a model’s lifetime, infrastructure write-ups commonly put inference at ~80–90% of compute dollars versus a minority share for training (Introl on inference vs training economics).
That shift shows up as an engineering problem. Inference is no longer “call an API.” Self-hosted stacks need model selection, runtime choice (Ollama, vLLM, Triton), autoscaling, placement, observability, and increasingly inference-aware routing. On Kubernetes, the Gateway API Inference Extension standardizes model-aware pools and endpoint picking, and llm-d sits above model servers for cache-aware scheduling and disaggregated serving.
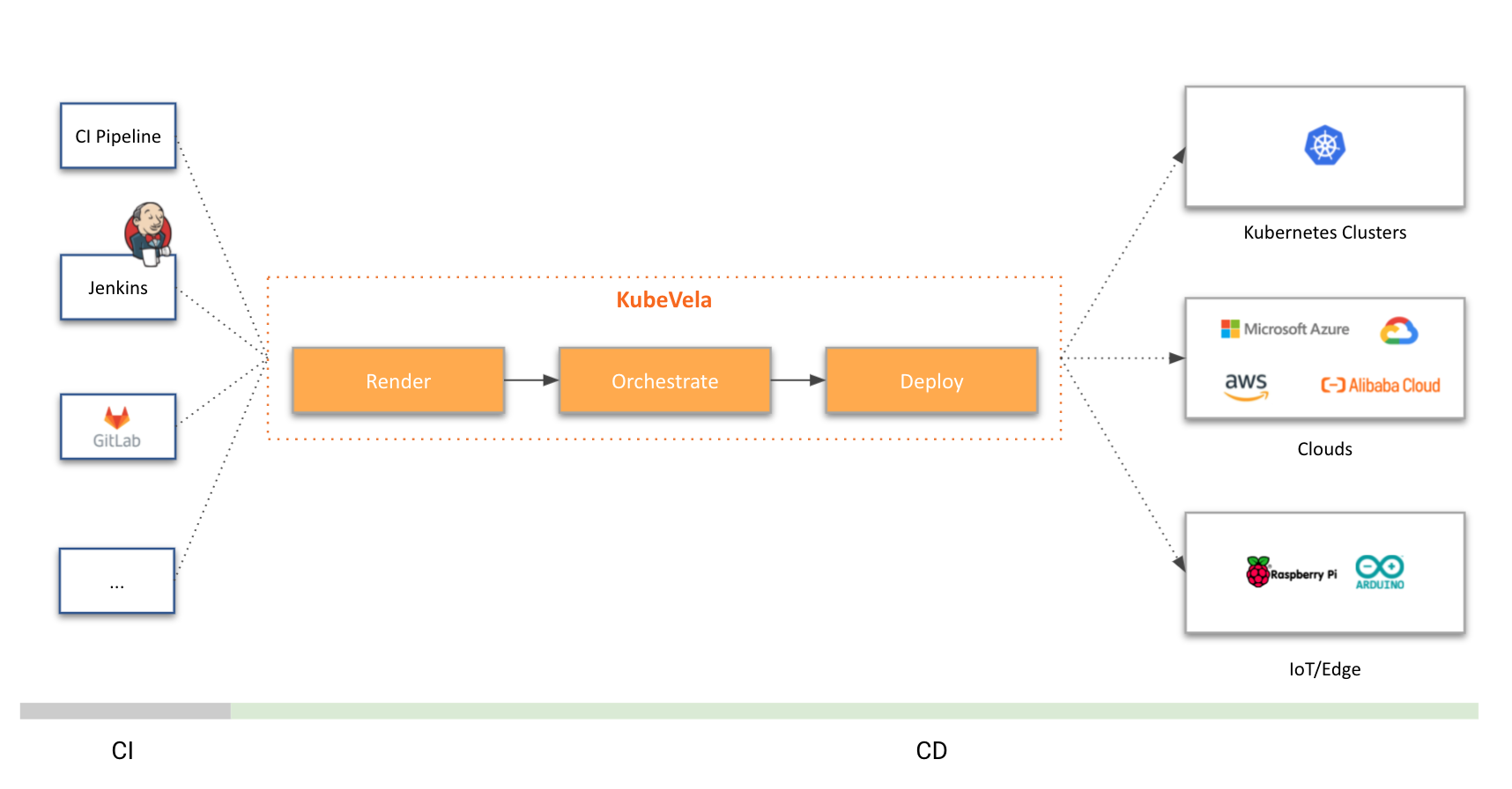
What still needs a clean answer is the application delivery layer: how platform teams expose a stable contract to product teams without every service owning a private copy of Deployment YAML, env vars, and tribal knowledge about backends.
KubeVela and the Open Application Model (OAM) were built for exactly that kind of packaging problem. Components describe what runs. Traits attach reusable capabilities. Policies and workflows handle placement, overrides, and delivery. This post applies that model to AI inference in a local-first proof of concept: an OpenAI-compatible facade as a Component, operational behaviors as Traits, multi-env promotion with built-in policies, and a deliberate seam toward llm-d without requiring a full GPU stack on day one.
The result is encouraging. KubeVela is a natural fit for composing and shipping inference apps while specialized projects own the heavy serving path. The sections below cover the design, the YAML, the measured results, and how the pieces fit together.