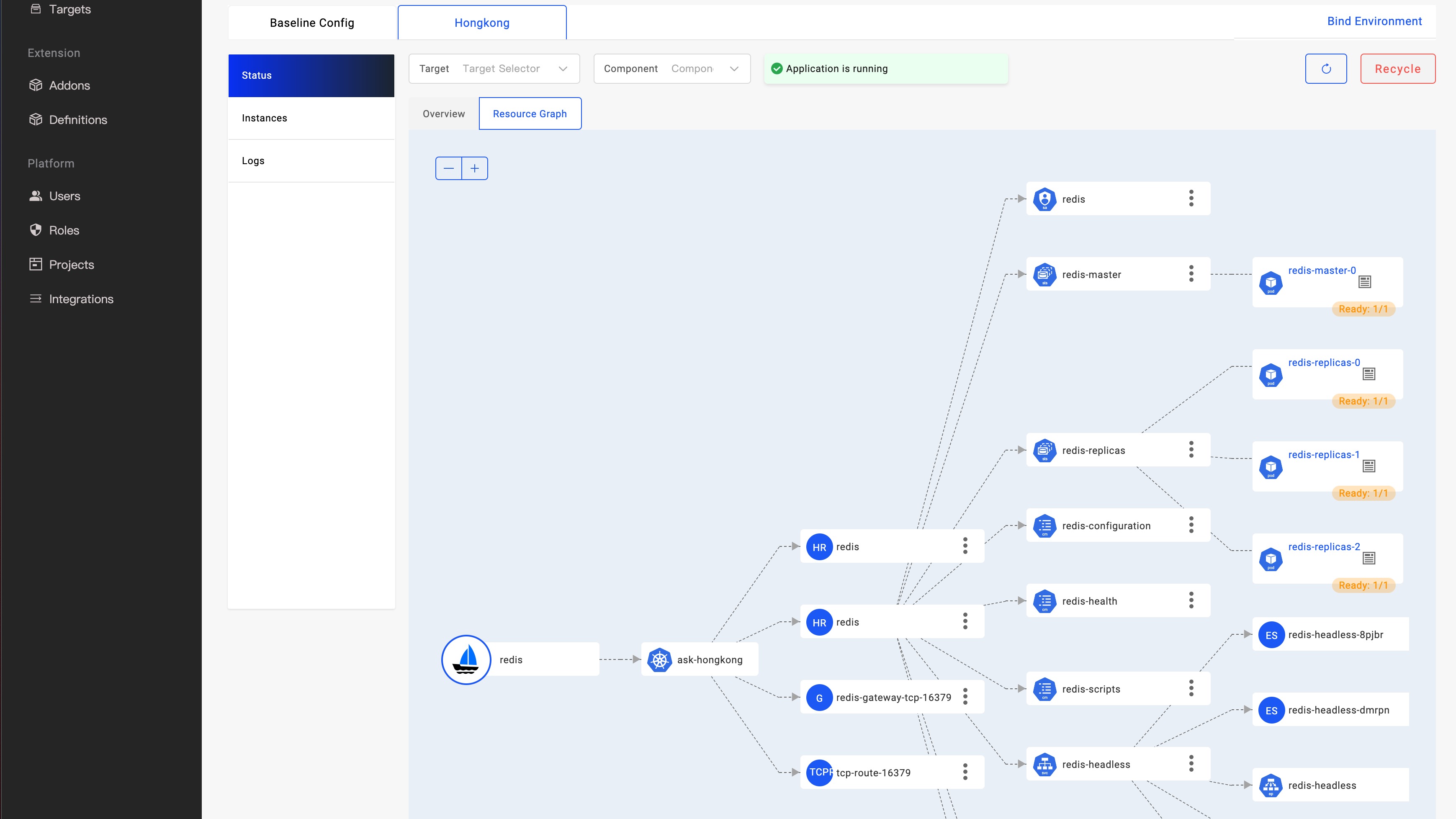
Deploying your OAM applications in the Napptive cloud-native application platform

Application Delivery on Kubernetes
The cloud-native landscape is formed by a fast-growing ecosystem of tools with the aim of improving the development of modern applications in a cloud environment. Kubernetes has become the de facto standard to deploy enterprise workloads by improving development speed, and accommodating the needs of a dynamic environment.
Kubernetes offers a comprehensive set of entities that enables any potential application to be deployed into it, independent of its complexity. This however has a significant impact from the point of view of its adoption. Kubernetes is becoming as complex as it is powerful, and that translates into a steep learning curve for newcomers into the ecosystem. Thus, this has generated a new trend focused on providing developers with tools that improve their day-to-day activities without losing the underlying capabilities of the underlying system.